http://xmodulo.com/2014/08/secure-lamp-server-centos-rhel.html
LAMP is a software stack composed of Linux (an operating system as a base layer), Apache (a web server that "sits on top" of the OS), MySQL (or MariaDB, as a relational database management system), and finally PHP (a server-side scripting language that is used to process and display information stored in the database).
In this article we will assume that each component of the stack is already up and running, and will focus exclusively on securing the LAMP server(s). We must note, however, that server-side security is a vast subject, and therefore cannot be addressed adequately and completely in a single article.
In this post, we will cover the essential must-do's to secure each part of the stack.
1) Use key-based authentication, whenever possible, instead of basic authentication (username + password) to log on to your server remotely. We assume that you have already created a key pair with your user name on your client machine and copied it to your server (see the tutorial).
2) Change the port where sshd will be listening on. A good idea for the port is a number higher than 1024:
3) Allow only protocol 2:
4) Configure the authentication timeout, do not allow root logins, and restrict which users may login, via ssh:
5) Allow only specific hosts (and/or networks) to login via ssh:
In the /etc/hosts.deny file:
In the /etc/hosts.allow file:
where XXX.YYY.ZZZ. represents the first 3 octets of an IPv4 network
address and AAA.BBB.CCC.DDD is an IPv4 address. With that setting, only
hosts from network XXX.YYY.ZZZ.0/24 and host AAA.BBB.CCC.DDD will be
allowed to connect via ssh. All other hosts will be disconnected before
they even get to the login prompt, and will receive an error like this:

(Do not forget to restart the sshd daemon to apply these changes: service sshd restart).
We must note that this approach is a quick and easy -but somewhat rudimentary- way of blocking incoming connections to your server. For further customization, scalability and flexibility, you should consider using plain iptables and/or fail2ban.
The following suggestions (2 through 5) refer to the /etc/httpd/conf/httpd.conf file:
2) Disable directory listing: this will prevent the browser from displaying the contents of a directory if there is no index.html present in that directory.
Delete the word Indexes in the Options directive:
Should read:
In addition, you need to make sure that the settings for directories and virtual hosts do not override this global configuration.
Following the example above, if we examine the settings for the /var/www/icons directory, we see that "Indexes MultiViews FollowSymLinks" should be changed to "None".
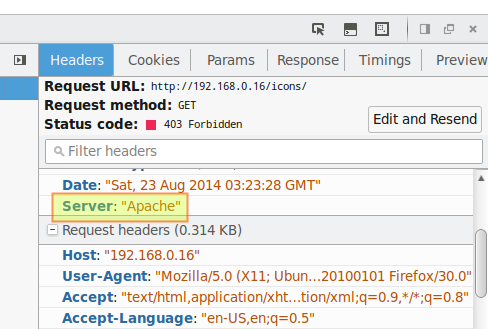
3) Hide Apache version, as well as module/OS information in error (e.g. Not Found and Forbidden) pages.
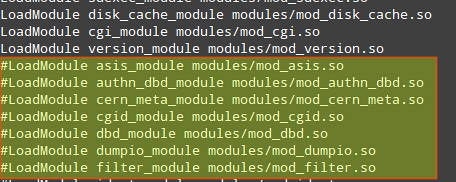
4) Disable unneeded modules by commenting out the lines where those modules are declared:
TIP: Disabling autoindex_module is another way to hide directory listings when there is not an index.html file in them.
5) Limit HTTP request size (body and headers) and set connection timeout:
For more directives and instructions on how to set them up, refer to the Apache docs.
1) If we have not set a root password for MySQL server during installation, now it's the time to do so, and remember: this is essential in a production environment.
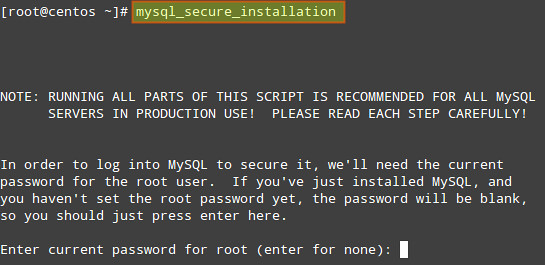
The process will continue:
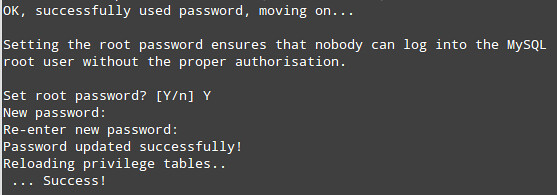
2) Remove the anonymous user:
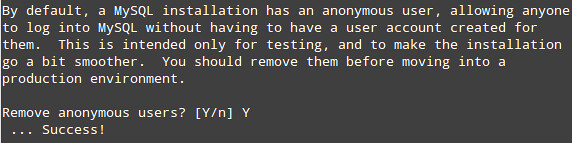
3) Only allow root to connect from localhost:

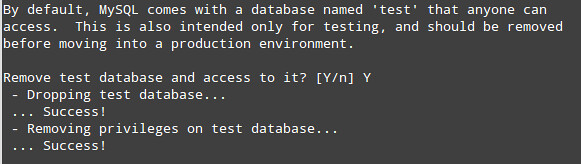
4) Remove the default database named test:
5) Apply changes:
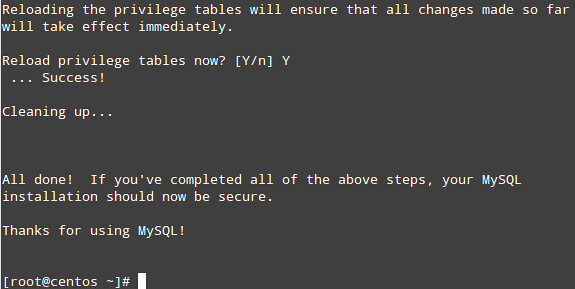
6) Next, we will edit some variables in the /etc/my.cnf file:
Don't forget to restart MySQL server with 'service mysqld restart'.
Now, when it comes to day-to-day database administration, you'll find the following suggestions useful:
First, retrieve the list of users from the user table:
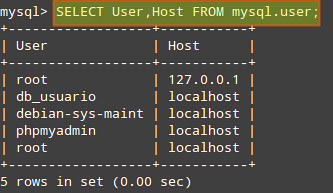
Make sure that each user only has access (and the minimum permissions) to the databases it needs. In the following example, we will check the permissions of user db_usuario:

You can then revoke permissions and access as needed.
1) Disable unnecessary modules:
We can display the list of current compiled in modules with the following command: php -m
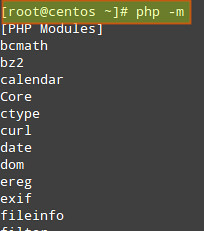
And disable those that are not needed by either removing or renaming the corresponding file in the /etc/php.d directory.
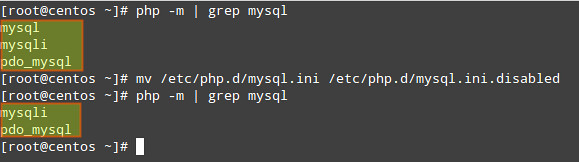
For example, since the mysql extension has been deprecated as of PHP v5.5.0 (and will be removed in the future), we may want to disable it:
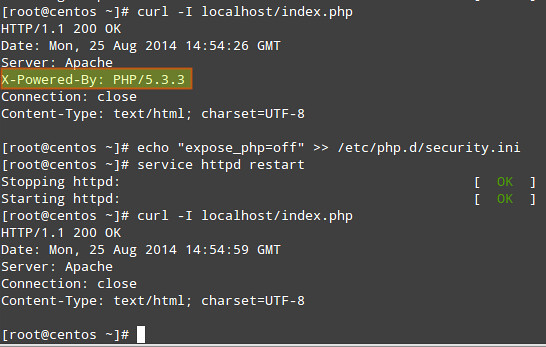
2) Hide PHP version information:
3) Set open_basedir to a few specific directories (in php.ini) in order to restrict access to the underlying file system:

4) Disable remote code/command execution along with easy exploitable functions such as exec(), system(), passthru(), eval(), and so on (in php.ini):

The following commands return the current versions of Apache, MySQL and PHP:
Then 'yum update [package]' can be used to update the package in order to have the latest security patches.
2) Make sure that configuration files can only be written by the root account:
3) Finally, if you have the chance, run these services (web server, database server, and application server) in separate physical or virtual machines (and protect communications between them via a firewall), so that in case one of them becomes compromised, the attacker will not have immediate access to the others. If that is the case, you may have to tweak some of the configurations discussed in this article. Note that this is just one of the setups that could be used to increase security in your LAMP server.
LAMP is a software stack composed of Linux (an operating system as a base layer), Apache (a web server that "sits on top" of the OS), MySQL (or MariaDB, as a relational database management system), and finally PHP (a server-side scripting language that is used to process and display information stored in the database).
In this article we will assume that each component of the stack is already up and running, and will focus exclusively on securing the LAMP server(s). We must note, however, that server-side security is a vast subject, and therefore cannot be addressed adequately and completely in a single article.
In this post, we will cover the essential must-do's to secure each part of the stack.
Securing Linux
Since you may want to manage your CentOS server via ssh, you need to consider the following tips to secure remote access to the server by editing the /etc/ssh/sshd_config file.1) Use key-based authentication, whenever possible, instead of basic authentication (username + password) to log on to your server remotely. We assume that you have already created a key pair with your user name on your client machine and copied it to your server (see the tutorial).
1
2
3
| PasswordAuthentication noRSAAuthentication yesPubkeyAuthentication yes |
1
| Port XXXX |
1
| Protocol 2 |
1
2
3
| LoginGraceTime 2mPermitRootLogin noAllowUsers gacanepa |
In the /etc/hosts.deny file:
1
| sshd: ALL |
1
| sshd: XXX.YYY.ZZZ. AAA.BBB.CCC.DDD |
(Do not forget to restart the sshd daemon to apply these changes: service sshd restart).
We must note that this approach is a quick and easy -but somewhat rudimentary- way of blocking incoming connections to your server. For further customization, scalability and flexibility, you should consider using plain iptables and/or fail2ban.
Securing Apache
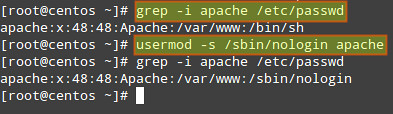
1) Make sure that the system user that is running Apache web server does not have access to a shell:
# grep -i apache /etc/passwd
If user apache has a default shell (such as /bin/sh), we must change it to /bin/false or /sbin/nologin:
# usermod -s /sbin/nologin apache
The following suggestions (2 through 5) refer to the /etc/httpd/conf/httpd.conf file:
2) Disable directory listing: this will prevent the browser from displaying the contents of a directory if there is no index.html present in that directory.
Delete the word Indexes in the Options directive:
1
2
3
4
5
| # The Options directive is both complicated and important. Please see# http://httpd.apache.org/docs/2.2/mod/core.html#options# for more information.#Options Indexes FollowSymLinks |
1
| Options None |
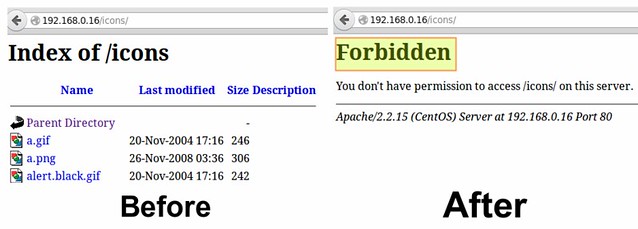
In addition, you need to make sure that the settings for directories and virtual hosts do not override this global configuration.
Following the example above, if we examine the settings for the /var/www/icons directory, we see that "Indexes MultiViews FollowSymLinks" should be changed to "None".
|
|
| Before | After |
1
2
| ServerTokens Prod # This means that the http response header will return just "Apache" but not its version numberServerSignature Off # The OS information is hidden |
4) Disable unneeded modules by commenting out the lines where those modules are declared:
TIP: Disabling autoindex_module is another way to hide directory listings when there is not an index.html file in them.
5) Limit HTTP request size (body and headers) and set connection timeout:
| Directive | Context | Example and meaning | ||
| LimitRequestBody | server config, virtual host, directory, .htaccess |
Limit file upload to 100 KiB max. for the uploads directory:
|
||
| LimitRequestFieldSize | server config, virtual host |
Change the allowed HTTP request header size to 4KiB (default is 8KiB), server wide:
|
||
| TimeOut | server config, virtual host |
Change the timeout from 300 (default if no value is used) to 120:
|
Securing MySQL Server
We will begin by running the mysql_secure_installation script which comes with mysql-server package.1) If we have not set a root password for MySQL server during installation, now it's the time to do so, and remember: this is essential in a production environment.
The process will continue:
2) Remove the anonymous user:
3) Only allow root to connect from localhost:
4) Remove the default database named test:
5) Apply changes:
6) Next, we will edit some variables in the /etc/my.cnf file:
1
2
3
4
| [mysqld]bind-address=127.0.0.1 # MySQL will only accept connections from localhostlocal-infile=0 # Disable direct filesystem accesslog=/var/log/mysqld.log # Enable log file to watch out for malicious activities |
Now, when it comes to day-to-day database administration, you'll find the following suggestions useful:
- If for some reason we need to manage our database remotely, we can do so by connecting via ssh to our server first to perform the necessary querying and administration tasks locally.
- We may want to enable direct access to the filesystem later if, for example, we need to perform a bulk import of a file into the database.
- Keeping logs is not as critical as the two things mentioned earlier, but may come in handy to troubleshoot our database and/or be aware of unfamiliar activities.
- DO NOT, EVER, store sensitive information (such as passwords, credit card numbers, bank PINs, to name a few examples) in plain text format. Consider using hash functions to obfuscate this information.
- Make sure that application-specific databases can be accessed only by the corresponding user that was created by the application to that purpose:
First, retrieve the list of users from the user table:
gacanepa@centos:~$ mysql -u root -p
Enter password: [Your root password here] mysql> SELECT User,Host FROM mysql.user;
Make sure that each user only has access (and the minimum permissions) to the databases it needs. In the following example, we will check the permissions of user db_usuario:
mysql> SHOW GRANTS FOR 'db_usuario'@'localhost';
You can then revoke permissions and access as needed.
Securing PHP
Since this article is oriented at securing the components of the LAMP stack, we will not go into detail as far as the programming side of things is concerned. We will assume that our web applications are secure in the sense that the developers have gone out of their way to make sure that there are no vulnerabilities that can give place to common attacks such as XSS or SQL injection.1) Disable unnecessary modules:
We can display the list of current compiled in modules with the following command: php -m
And disable those that are not needed by either removing or renaming the corresponding file in the /etc/php.d directory.
For example, since the mysql extension has been deprecated as of PHP v5.5.0 (and will be removed in the future), we may want to disable it:
# php -m | grep mysql
# mv /etc/php.d/mysql.ini /etc/php.d/mysql.ini.disabled
# mv /etc/php.d/mysql.ini /etc/php.d/mysql.ini.disabled
2) Hide PHP version information:
# echo "expose_php=off" >> /etc/php.d/security.ini [or modify the security.ini file if it already exists]
3) Set open_basedir to a few specific directories (in php.ini) in order to restrict access to the underlying file system:
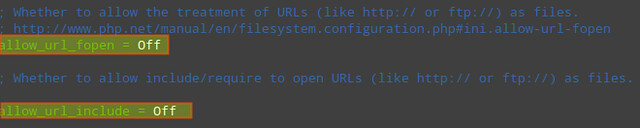
4) Disable remote code/command execution along with easy exploitable functions such as exec(), system(), passthru(), eval(), and so on (in php.ini):
1
2
3
| allow_url_fopen = Offallow_url_include = Offdisable_functions = "exec, system, passthru, eval" |
Summing Up
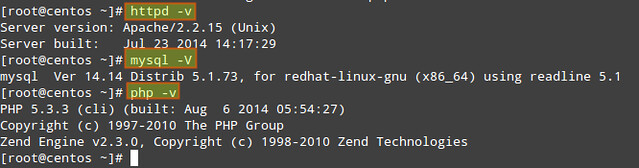
1) Keep packages updated to their most recent version (compare the output of the following commands with the output of 'yum info [package]'):The following commands return the current versions of Apache, MySQL and PHP:
# httpd -v
# mysql -V (capital V)
# php -v
# mysql -V (capital V)
# php -v
Then 'yum update [package]' can be used to update the package in order to have the latest security patches.
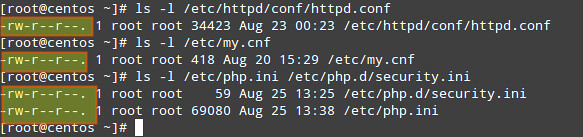
2) Make sure that configuration files can only be written by the root account:
# ls -l /etc/httpd/conf/httpd.conf
# ls -l /etc/my.cnf
# ls -l /etc/php.ini /etc/php.d/security.ini
# ls -l /etc/my.cnf
# ls -l /etc/php.ini /etc/php.d/security.ini
3) Finally, if you have the chance, run these services (web server, database server, and application server) in separate physical or virtual machines (and protect communications between them via a firewall), so that in case one of them becomes compromised, the attacker will not have immediate access to the others. If that is the case, you may have to tweak some of the configurations discussed in this article. Note that this is just one of the setups that could be used to increase security in your LAMP server.





 Figure 1. Example Playbook That Will Upgrade Apache to the Latest Version
Figure 1. Example Playbook That Will Upgrade Apache to the Latest Version
 Figure 2. Example of ad hoc Command Showing Uptime Output for All Targets
Figure 2. Example of ad hoc Command Showing Uptime Output for All Targets
 Figure 3. In this example, Ansible pings the target hosts using the ping module.
Figure 3. In this example, Ansible pings the target hosts using the ping module.
 Figure 4. The /etc/hosts File for My Test Cluster
Figure 4. The /etc/hosts File for My Test Cluster
 Figure 5. My Simple Playbook to Execute STIG Scripts on All Targets
Figure 5. My Simple Playbook to Execute STIG Scripts on All Targets
 Figure 6. Output Showing a Successful STIG Playbook Execution
Figure 6. Output Showing a Successful STIG Playbook Execution






{kind=link}