http://www.linuxjournal.com/content/devops-better-sum-its-parts
Most of us longtime system administrators get a little nervous when
people start talking about DevOps. It's an IT topic surrounded by
a lot of mystery and confusion, much like the term "Cloud
Computing"
was a few years back. Thankfully, DevOps isn't something sysadmins need
to fear. It's not software that allows developers to do the job of the
traditional system administrator, but rather it's just a concept making
both development and system administration better. Tools like Chef and
Puppet (and Salt Stack, Ansible, New Relic and so on) aren't
"DevOps", they're
just tools that allow IT professionals to adopt a DevOps mindset. Let's
start there.
What Is DevOps?
Ask ten people to define DevOps, and you'll likely get 11 different
answers. (Those numbers work in binary too, although I suggest a larger
sample size.) The problem is that many folks confuse DevOps with DevOps
tools. These days, when people ask me, "What is DevOps?", I generally
respond:
"DevOps isn't a thing, it's a way of doing a thing."
The worlds of system administration and development historically
have been very separate. As a sysadmin, I tend to think very differently about
computing from how a developer does. For me, things like scalability and redundancy
are critical, and my success often is gauged by uptime. If things are
running, I'm successful. Developers have a different way of approaching
their jobs, and need to consider things like efficiency, stability,
security and features. Their success often is measured by usability.
Hopefully, you're thinking the traits I listed are important for both
development
and system administration. In fact, it's that mindset
from which DevOps was born. If we took the best practices from the
world of development, and infused them into the processes of operations,
it would make system administration more efficient, more reliable and
ultimately better. The same is true for developers. If they can begin to
"code" their own hardware as part of the development process, they can
produce and deploy code more quickly and more efficiently. It's basically
the Reese's Peanut Butter Cup of IT. Combining the strengths of both
departments creates a result that is better than the sum of its parts.
Once you understand what DevOps really is, it's easy to see how people
confuse the tools (Chef, Puppet, New Relic and so on) for DevOps itself. Those
tools make it so easy for people to adopt the DevOps mindset, that they
become almost synonymous with the concept itself. But don't be seduced
by the toys—an organization can shift to a very successful DevOps way
of doing things simply by focusing on communication and cross-discipline
learning. The tools make it easier, but just like owning a rake doesn't
make someone a farmer, wedging DevOps tools into your organization
doesn't create a DevOps team for you. That said, just like any farmer
appreciates a good rake, any DevOps team will benefit from using the
plethora of tools in the DevOps world.
The System Administrator's New Rake
In this article, I want to talk about using DevOps tools as a system
administrator. If you're a sysadmin who isn't using a configuration
management tool to keep track of your servers, I urge you to check one
out. I'm going to talk about Chef, because for my day job, I recently
taught a course on how to use it. Since you're basically learning the
concepts behind DevOps tools, it doesn't matter that you're focusing on
Chef. Kyle Rankin is a big fan of Puppet, and conceptually, it's just
another type of rake. If you have a favorite application that isn't
Chef, awesome.
If I'm completely honest, I have to admit I was hesitant to learn Chef,
because it sounded scary and didn't seem to do anything I wasn't
already doing with Bash scripts and cron jobs. Plus, Chef uses the Ruby
programming language for its configuration files, and my programming
skills peaked with:
10 PRINT "Hello!"
20 GOTO 10
Nevertheless, I had to learn about it so I could teach the class. I can
tell you with confidence, it was worth it. Chef requires basically zero
programming knowledge. In fact, if no one mentioned that its configuration
files were Ruby, I'd just have assumed the syntax for the conf files was
specific and unique. Weird config files are nothing new, and honestly,
Chef's config files are easy to figure out.
Chef: Its Endless Potential
DevOps is a powerful concept, and as such, Chef can do amazing
things. Truly. Using creative "recipes", it's possible to spin up hundreds
of servers in the cloud, deploy apps, automatically scale based on need
and treat every aspect of computing as if it were just a function to
call from simple code. You can run Chef on a local server. You can
use the cloud-based service from the Chef company instead of hosting
a server. You even can use Chef completely server-less, deploying the
code on a single computer in solo mode.
Once it's set up, Chef supports multiple environments of similar
infrastructures. You can have a development environment that is completely
separate from production, and have the distinction made completely
by the version numbers of your configuration files. You can have your
configurations function completely platform agnostically, so a recipe
to spin up an Apache server will work whether you're using CentOS,
Ubuntu, Windows or OS X. Basically, Chef can be the central resource
for organizing your entire infrastructure, including hardware, software,
networking and even user management.
Thankfully, it doesn't have to do all that. If using Chef meant turning
your entire organization on its head, no one would ever adopt it. Chef
can be installed small, and if you desire, it can grow to handle more
and more in your company. To continue with my farmer analogy, Chef can
be a simple garden rake, or it can be a giant diesel combine tractor. And
sometimes, you just need a garden rake. That's what you're going to learn
today. A simple introduction to the Chef way of doing things, allowing
you to build or not build onto it later.
The Bits and Pieces
Initially, this was going to be a multipart article on the specifics of
setting up Chef for your environment. I still might do a series like
that for Chef or another DevOps configuration automation package,
but here I want everyone to understand not only DevOps itself, but what
the DevOps tools do. And again, my example will be Chef.
At its heart, Chef functions as a central repository for all your
configuration files. Those configuration files also include the ability
to carry out functions on servers. If you're a sysadmin, think of it
as a central, dynamic /etc directory along with a place all your Bash
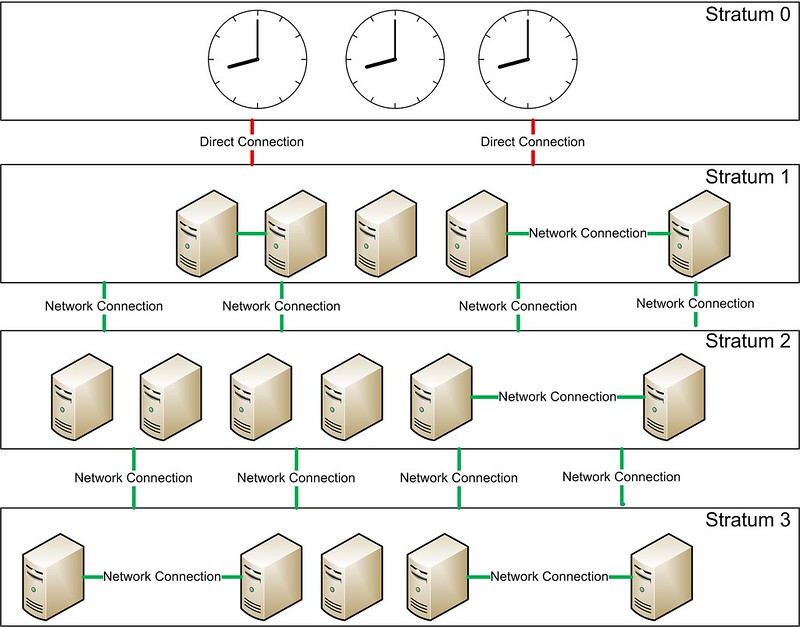
and Perl scripts are held. See Figure 1 for a visual on how Chef's
information flows.

Figure 1. This is the basic Chef setup, showing how data flows.
The Admin Workstation is the computer at which configuration files
and scripts are created. In the world of Chef, those are called
cookbooks and recipes, but basically, it's the place all the human-work
is done. Generally, the local Chef files are kept in a revision control
system like Git, so that configurations can be rolled back in the case of
a failure. This was my first clue that DevOps might make things better for
system administrators, because in the past all my configuration revision
control was done by making a copy of a configuration file before editing
it, and tacking a .date at the end of the filename. Compared to the
code revision tools in the developer's world, that method (or at least
my method) is crude at best.
The cookbooks and recipes created on the administrator workstation
describe things like what files should be installed on the server
nodes, what configurations should look like, what applications should be
installed and stuff like that. Chef does an amazing job of being
platform-neutral, so if your cookbook installs Apache, it generally can
install
Apache without you needing to specify what type of system it's
installing
on. If you've ever been frustrated by Red Hat variants calling Apache
"httpd", and Debian variants calling it
"apache2", you'll love Chef.
Once you have created the cookbooks and recipes you need to configure your
servers, you upload them to the Chef server. You can connect to the Chef
server via its Web interface, but very little actual work is done via the
Web interface. Most of the configuration is done on the command line of
the Admin Workstation. Honestly, that is something a little confusing
about Chef that gets a little better with every update. Some things
can be modified via the Web page interface, but many things can't. A few
things can
only be modified on the Web page, but it's not always clear
which or why.
With the code, configs and files uploaded to the Chef Server, the
attention is turned to the nodes. Before a node is part of the Chef
environment, it must be "bootstrapped". The process isn't difficult, but
it is required in order to use Chef. The client software is installed on
each new node, and then configuration files and commands are pulled from
the Chef server. In fact, in order for Chef to function, the nodes must
be configured to poll the server periodically for any changes. There is
no "push" methodology to send changes or updates to the node, so regular
client updates are important. (These are generally performed via cron.)
At this point, it might seem a little silly to have all those extra steps
when a simple FOR loop with some SSH commands could accomplish the same
tasks from the workstation, and have the advantage of no Chef client
installation or periodic polling. And I confess, that was my thought at
first too. When programs like Chef really prove their worth, however,
is when the number of nodes begins to scale up. Once the admittedly
complex setup is created, spinning up a new server is literally a single
one-liner to bootstrap a node. Using something like Amazon Web Services,
or Vagrant, even the creation of the computers themselves can be part
of the Chef process.
To Host or Not to Host
The folks at Chef have made the process of getting a Chef Server
instance as simple as signing up for a free account on their cloud
infrastructure. They maintain a "Chef Server" that allows you to upload
all your code and configs to their server, so you need to worry
only about your nodes. They even allow you to connect five of your server
nodes for free. If you have a small environment, or if you don't have the
resources to host your own Chef Server, it's tempting just to use their
pre-configured cloud service. Be warned, however, that it's free
only because they hope you'll start to depend on the service and eventually
pay for connecting more than those initial five free nodes.
They have an enterprise-based self-hosted solution that moves the Chef
Server into your environment like Figure 1 shows. But it's important
to realize that Chef is open source, so there is a completely free,
and fully functional open-source version of the server you can download
and install into your environment as well. You do lose their support,
but if you're just starting out with Chef or just playing with it,
having the open-source version is a smart way to go.
How to Begin?
The best news about Chef is that incredible resources exist
for learning how to use it. On the
http://getchef.com Web
site, there is a video
series outlining a basic setup for installing Apache on your server
nodes as an example of the process. Plus, there's great documentation
that describes the installation process of the open-source Chef Server,
if that's the path you want to try.
Once you're familiar with how Chef works (really, go through the training
videos, or find other Chef fundamentals training somewhere), the next
step is to check out the vibrant Chef community. There are cookbooks and
recipes for just about any situation you can imagine. The cookbooks are
just open-source code and configuration files, so you can tweak them to
fit your particular needs, but like any downloaded code, it's nice to
start with something and tweak it instead of starting from scratch.
DevOps is not a scary new trend invented by developers in order to get
rid of pesky system administrators. We're not being replaced by code,
and our skills aren't becoming useless. What a DevOps mindset means is
that we get to steal the awesome tools developers use to keep their code
organized and efficient, while at the same time we can hand off some of the
tasks we hate (spinning up test servers for example) to the developers, so
they can do their jobs better, and we can focus on more important sysadmin
things. Tearing down that wall between development and operations truly
makes everyone's job easier, but it requires communication, trust and
a few good rakes in order to be successful. Check out a tool like Chef,
and see if DevOps can make your job easier and more awesome.
Resources
Chef Fundamentals Video Series:
https://learn.getchef.com/fundamentals-series
Chef Documentation:
https://docs.getchef.com
Community Cookbooks/Tools:
https://supermarket.getchef.com



 Figure 1. JavaScript can be used everywhere, on the client and the server
sides.
Figure 1. JavaScript can be used everywhere, on the client and the server
sides.
 Figure 2. Apache and traditional Web servers run a separate thread for each
request.
Figure 2. Apache and traditional Web servers run a separate thread for each
request.
 Figure 3. Node runs a single thread for all requests.
Figure 3. Node runs a single thread for all requests.