In Linux system administration, you will encounter situations where
you need to disable, suspend, or reset a user account for various
reasons, such as security concerns, incident investigations, temporary
suspensions, or transitions to a different system.
To achieve this, you can use various Linux commands, such as locking a user account with the usermod command, locking a user account with the passwd command, expiring a user account with the chage command, or directly modifying the /etc/shadow file to disable a user account.
In this article, I'll guide you on how to disable, lock, or expire a user account on a Linux system without removing it.
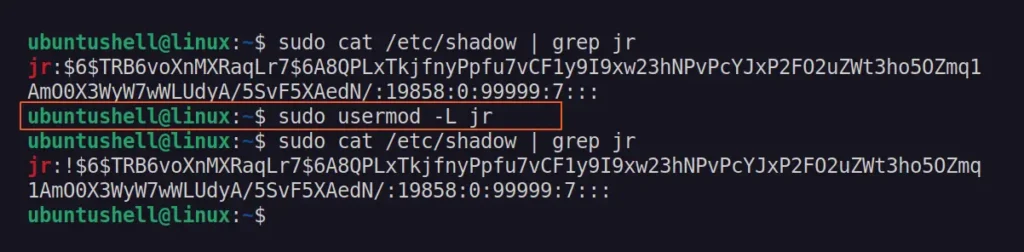
The usermod
command is a robust tool for modifying user account information, such
as the username, user ID, home directory path, or locking a user
account.
You can use its -L option with a username to lock a user account by putting a ! in front of the encrypted password hash in the "/etc/shadow" file.
$ sudo usermod -L <username>
Once
the user account is locked using this method, it can't be accessed
directly, via SSH, or by any method unless the account is released from
the locked state using the -U option.
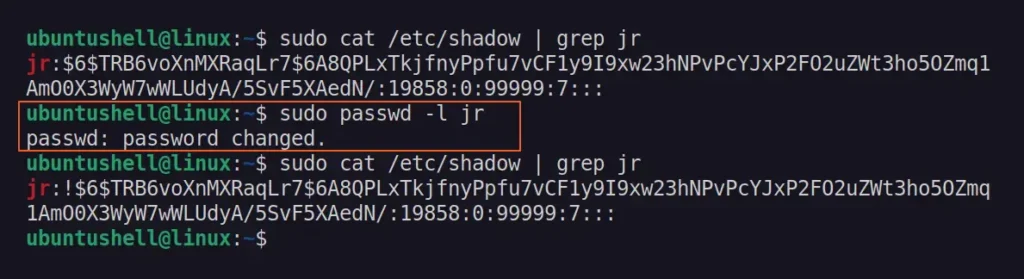
The passwd
command is another fantastic tool used to manage various properties of a
user password, such as deleting the password, expiring the password, or
locking the password.
The user account locking mechanism using passwd is identical to the previous command that places a ! as a prefix before the encrypted password hash in the "/etc/shadow" file.
If, for any reason, you were unable to use the previous command, you can use the passwd command with the -l option followed by the user account.
$ sudo passwd -l <username>
To unlock the user account, you can use the -U option.
The usermod
command we previously used for locking a user account can also be used
to expire a user account password, preventing the target user from
accessing their account with a "Your account has expired" message.
The
user account expiry date typically gets set to a future date or no
expiry date by default, but when using this command to expire a user
account, it sets the expiry date in the past, usually to the Unix epoch
(January 1, 1970), making the account inaccessible.
So, to expire a user account using the usermod command, thereby disallowing the user from logging in from any source, you can run.
$ sudo usermod --expiredate 1 <username>
Once the user account expires, attempting to access it, whether by the user or someone else, will result in encountering the "Connection closed" message.
To unlock the user back to the normal state, you can run:
The chage command is identical to the passwd command for altering user account details, with a specific focus on modifying the user account expiry date.
Let's say you want to set a user account to expire. For that purpose, you can use the -E option with 0 for immediate expiration or provide a future date in "YYYY-MM-DD" format.
To remove the expiration from the user account, you can run:
$ sudo chage -E '' <username>
Method 5: Modify the /etc/shadow to Disable User Account
This
method is geared towards experienced users who are comfortable with the
command-line and familiar with the Linux filesystem. Thus, most of the
commands previously used to disable a user account involved adding a ! prefix in front of user password hash in the "/etc/shadow" file.
These
commands served as a front-end for the task, but if you lack access to
them and need to manually disable a user account, you can edit the file,
find the user, and prepend a ! to their password hash.
$ sudo nano /etc/shadow
Once you are done, save and close the file. Now, when the user tries to access their account, they encounter the "Permission denied" error. To unlock the user account again, simply remove the exclamation next to their password hash.
Another
approach to disabling a user account is to set their login shell to
nologin, which allows you to block or deactivate their ability to log
in. Simply execute the following command to change the user shell to nologin:
$ sudo usermod -s /sbin/nologin <username>
Once the user's login shell is set to nologin, attempting direct account access from the system will trigger the "This account is currently not available." message, while SSH attempts result in a "Connection closed" message.
To undo this change, you can set the user login back to the original shell (assuming bash) by running the following command:
$ sudo usermod -s $(which bash) <username>
All
the methods mentioned in this article are effective ways to disable,
lock, or set an expiration date for a user account using either
command-line or manual methods.
Before
proceeding with any of these methods, ensure that you understand the
implications, as they can affect the user's ability to access their
account.
Accidentally deleting a user account could be disastrous,
so it's advisable to have a backup in place, especially if you're new
to using a Linux system.
In recent years, DevOps has emerged as a critical discipline that
merges software development (Dev) with IT operations (Ops). It aims to
shorten the development lifecycle and provide continuous delivery with
high software quality.
As the demand for faster development cycles and more reliable
software increases, professionals in the field constantly seek tools and
practices to enhance their efficiency and effectiveness.
Enter the realm of free and open-source tools – a goldmine for DevOps practitioners looking to stay ahead of the curve.
This article is designed for DevOps professionals, whether you’re
just starting or looking to refine your craft. We’ve curated a list of
ten essential free and open-source tools that have proven themselves and
stand out for their effectiveness and ability to streamline the DevOps
process.
These tools cover a range of needs, from continuous integration and
delivery (CI/CD) to infrastructure as code (IaC), monitoring, and more,
ensuring you have the resources to tackle various challenges head-on.
Additionally, these tools have become essential for every DevOps
engineer to know and use. Getting the hang of them can boost your career
in the field. So, based on our hands-on industry experience, we’ve
compiled this list for you. But before we go further, let’s address a
fundamental question.
What is DevOps?
DevOps is a set of practices and methodologies that brings together
the development (those who create software) and operations (those who
deploy and maintain software) teams.
Instead of working in separate silos, these teams collaborate closely
throughout the entire software lifecycle, from design through the
development process to production support.
But what exactly does it mean, and why is it so important? Let’s break it down in an easy-to-understand way.
Imagine you’re part of a team creating a puzzle. The developers are
those who design and make the puzzle pieces, while the operations team
is responsible for putting the puzzle together and making sure it looks
right when completed.
In traditional settings, these teams might work separately, leading
to miscommunication, delays, and a final product that doesn’t fit
perfectly.
DevOps ensures everyone works together from the start, shares
responsibilities, and communicates continuously to solve problems faster
and more effectively. It’s the bridge that connects the creation and
operation of software into a cohesive, efficient, and productive
workflow.
In other words, DevOps is the practice that ensures both teams are
working in tandem and using the same playbook. The end game is to
improve software quality and reliability and speed up the time it takes
to deliver software to the end users.
Key Components of DevOps
Continuous Integration (CI): This practice involves
developers frequently merging their code changes into a central
repository, where automated builds and tests are run. The idea is to
catch and fix integration errors quickly.
Continuous Delivery (CD): Following CI, continuous
delivery automates the delivery of applications to selected
infrastructure environments. This ensures that the software can be
deployed at any time with minimal manual intervention.
Automation: Automation is at the heart of DevOps.
It applies to testing, deployment, and even infrastructure provisioning,
helping reduce manual work, minimize errors, and speed up processes.
Monitoring and Feedback: Constant application and
infrastructure performance monitoring is crucial. It helps quickly
identify and address issues. Feedback loops allow for continuous
improvement based on real user experiences.
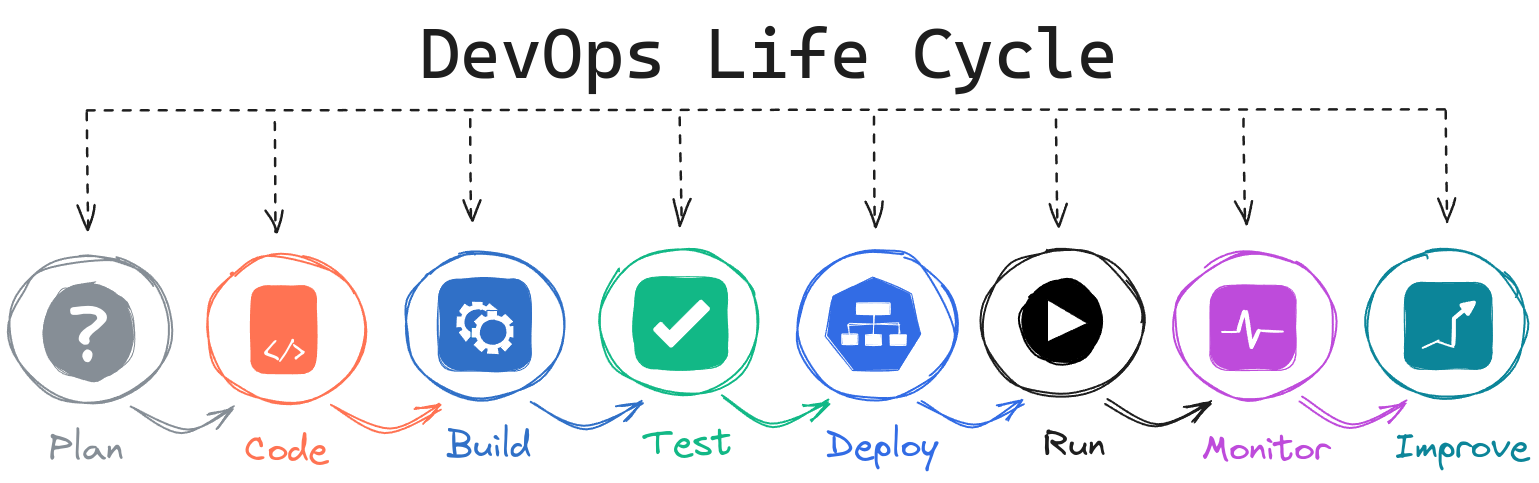
DevOps Life Cycle
Grasping the various stages of the DevOps life cycle is key to fully
comprehending the essence of the DevOps methodology. So, if you’re just
entering this field, we’ve broken them down below to clarify things.
DevOps Life Cycle
Plan: In this initial stage, the team decides on
the software’s features and capabilities. It’s like laying out a
blueprint for what needs to be built.
Code: Developers write code to create the software
once the plan is in place. This phase involves turning ideas into
tangible products using programming languages and tools.
Build: After coding, the next step is to compile
the code into a runnable application, which involves converting source
code into an executable program.
Test: Testing is crucial for ensuring the quality
and reliability of the software. In this phase, automated tests are run
to find and fix bugs or issues before the software is released to users.
Deploy & Run: Once the software passes all
tests, it’s time to release it and run it into the production
environment where users can access it. Deployment should be automated
for frequent and reliable releases with minimal human intervention.
Monitor: Monitoring involves collecting, analyzing,
and using data about the software’s performance and usage to identify
issues, trends, or areas for improvement.
Improve: The final stage closes the loop, where
feedback from monitoring and end-user experiences is used to make
informed decisions on future improvements or changes.
However, to make this happen, we need specific software tools. The
good news is that the top ones in the DevOps ecosystem are open-source!
Here they are.
Linux: The DevOps’ Backbone
We’ve left Linux
out of the numbered list below of the key DevOps tools, not because
it’s unimportant, but because calling it just a ‘tool’ doesn’t do it
justice. Linux is the backbone of all DevOps activities, making
everything possible.
In simple terms, DevOps as we know it wouldn’t exist without Linux. It’s like the stage where all the DevOps magic happens.
We’re highlighting this to underline how crucial it is to have Linux skills if you’re planning to dive into the DevOps world.
Understanding the basics of how the Linux operating system works is
fundamental. Without this knowledge, achieving high expertise and
success in DevOps can be quite challenging.
1. Docker
Docker
and container technology have become foundational to the DevOps
methodology. They have revolutionized how developers build, ship, and
run applications, unprecedentedly bridging the gap between code and
deployment.
Containers allow a developer to package an application with all of
its needed parts, such as libraries and other dependencies, and ship it
as one package. This consistency significantly reduces the “it works on
my machine” syndrome, streamlining the development lifecycle and
enhancing productivity.
At the same time, the Docker containers can be started and stopped in
seconds, making it easier to manage peak loads. This flexibility is
crucial in today’s agile development processes and continuous delivery
cycles, allowing teams to push updates to production faster and more
reliably.
Let’s not forget that containers also provide isolation between
applications, ensuring that each application and its runtime environment
can be secured separately. This helps minimize conflict between running
applications and enhances security by limiting the surface area for
potential attacks.
Even though containers were around before Docker arrived, it made
them popular and set them up as a key standard widely used in the IT
industry. These days, Docker remains the top choice for working with
containers, making it an essential skill for all DevOps professionals.
2. Kubernetes
We’ve already discussed containers. Now, let’s discuss the main tool
for managing them, known as the ‘orchestrator’ in the DevOps ecosystem.
While there are other widely used alternatives in the container
world, such as Podman, LXC, etc., when we talk about container
orchestration, one name stands out as the ultimate solution – Kubernetes.
As a powerful, open-source platform for automating the deployment,
scaling, and management of containerized applications, Kubernetes has
fundamentally changed how development and operations teams work together
to deliver applications quickly and efficiently by automating the
distribution of applications across a cluster of machines.
It also enables seamless application scaling in response to
fluctuating demand, ensuring optimal resource utilization and
performance. Abstracting the complexity of managing infrastructure,
Kubernetes allows developers to focus on writing code and operations
teams to concentrate on governance and automation.
Moreover, Kubernetes integrates well with CI/CD pipelines, automating
the process from code check-in to deployment, enabling teams to release
new features and fixes rapidly and reliably.
In simple terms, knowing how to use Kubernetes is essential for every
professional in the DevOps field. If you’re in this industry, learning
Kubernetes is a must.
3. Python
At the heart of DevOps is the need for automation. Python‘s
straightforward syntax and extensive library ecosystem allow DevOps
engineers to write scripts that automate deployments, manage
configurations, and streamline the software development lifecycle.
Its wide adoption and support have led to the development of numerous
modules and tools specifically designed to facilitate DevOps processes.
Whether it’s Ansible for configuration management, Docker for
containerization, or Jenkins for continuous integration, Python serves
as the glue that integrates these tools into a cohesive workflow,
enabling seamless operations across different platforms and
environments.
Moreover, it is pivotal in the IaC (Infrastructure as Code) paradigm,
allowing teams to define and provision infrastructure through code.
Libraries such as Terraform and CloudFormation are often used with
Python scripts to automate the setup and management of servers,
networks, and other cloud resources.
We can continue by saying that Python’s data analysis and
visualization capabilities are invaluable for monitoring performance,
analyzing logs, and identifying bottlenecks. Tools like Prometheus and
Grafana, often integrated with Python, enable DevOps teams to maintain
high availability and performance.
Even though many other programming languages, such as Golang, Java,
Ruby, and more, are popular in the DevOps world, Python is still the top
choice in the industry. This is supported by the fact that, according
to GitHub, the biggest worldwide code repository, Python has been the most used language over the past year.
4. Git
Git,
a distributed version control system, has become indispensable for
DevOps professionals. First and foremost, it enables team collaboration
by allowing multiple developers to work on the same project
simultaneously without stepping on each other’s toes.
It provides a comprehensive history of project changes, making it
easier to track progress, revert errors, and understand the evolution of
a codebase. This capability is crucial for maintaining the speed and
quality of development that DevOps aims for.
Moreover, Git integrates seamlessly with continuous
integration/continuous deployment (CI/CD) pipelines, a core component of
DevOps practices. Understanding Git also empowers DevOps professionals
to implement and manage code branching strategies effectively, such as
the popular Git flow.
A lot of what DevOps teams do begins with a simple Git command. It
kicks off a series of steps in the CI/CD process, ultimately leading to a
completed software product, a functioning service, or a settled IT
infrastructure.
In conclusion, for industry professionals, commands like “pull,” “push,” “commit,” and so on are the DevOps alphabet. Therefore, getting better and succeeding in this field depends on being skilled with Git.
5. Ansible
Ansible
is at the heart of many DevOps practices, an open-source automation
tool that plays a pivotal role in infrastructure as code, configuration
management, and application deployment. Mastery of Ansible skills has
become increasingly important for professionals in the DevOps field, and
here’s why.
Ansible allows teams to automate software provisioning, configuration
management, and application deployment processes. This automation
reduces the potential for human error and significantly increases
efficiency, allowing teams to focus on more strategic tasks rather than
repetitive manual work.
One of Ansible’s greatest strengths is its simplicity. Its use of
YAML for playbook writing makes it accessible to those who may not have a
strong background in scripting or programming, bridging the gap between
development and operations teams.
In addition, what sets Ansible apart is that it’s agentless. This
means there’s no need to install additional software on the nodes or
servers it manages, reducing overhead and complexity. Instead, Ansible
uses SSH for communication, further simplifying the setup and execution
of tasks.
It also boasts a vast ecosystem of modules and plugins, making it
compatible with a wide range of operating systems, cloud platforms, and
software applications. This versatility ensures that DevOps
professionals can manage complex, heterogeneous environments
efficiently.
While it’s not mandatory for a DevOps engineer, like containers,
Kubernetes, and Git are, you’ll hardly find a job listing for a DevOps
role that doesn’t ask for skills to some level in Ansible or any of the
other alternative automation tools, such as Chief, Puppet, etc. That’s
why proficiency is more than advisable.
6. Jenkins
Jenkins
is an open-source automation server that facilitates continuous
integration and continuous delivery (CI/CD) practices, allowing teams to
build, test, and deploy applications more quickly and reliably.
It works by monitoring a version control system for changes,
automatically running tests on new code, and facilitating the deployment
of passing builds to production environments.
Due to these qualities, just as Kubernetes is the go-to choice for
container orchestration, Jenkins has become the go-to tool for CI/CD
processes, automating the repetitive tasks involved in the software
development lifecycle, such as building code, running tests, and
deploying to production.
By integrating with a multitude of development, testing, and
deployment tools, Jenkins serves as the backbone of a streamlined CI/CD
pipeline. It enables developers to integrate changes to the project and
makes it easier for teams to detect issues early on.
Proficiency in Jenkins is highly sought after in the DevOps field. As
organizations increasingly adopt DevOps practices, the demand for
professionals skilled in Jenkins and similar technologies continues to
rise.
Mastery of it can open doors to numerous opportunities, from roles
focused on CI/CD pipeline construction and maintenance to DevOps
engineering positions.
7. Terraform / OpenTofu
In recent years, Terraform
has emerged as a cornerstone for DevOps professionals. But what exactly
is Terraform? Simply put, it’s a tool created by HashiCorp that allows
you to define and provision infrastructure through code.
It allows developers and IT professionals to define their
infrastructure using a high-level configuration language, enabling them
to script the setup and provisioning of servers, databases, networks,
and other IT resources. By doing so, Terraform introduces automation,
repeatability, and consistency into the often complex infrastructure
management process.
This approach, called Infrastructure as Code (IaC), allows
infrastructure management to be automated and integrated into the
development process, making it more reliable, scalable, and transparent.
With Terraform, DevOps professionals can seamlessly manage multiple
cloud services and providers, deploying entire infrastructures with a
single command. This capability is crucial in today’s multi-cloud
environments, as it ensures flexibility, avoids vendor lock-in, and
saves time and resources.
Moreover, it integrates very well with distributed version control
systems such as Git, allowing teams to track and review changes to the
infrastructure in the same way they manage application code.
However, HashiCorp recently updated Terraform’s licensing, meaning it’s no longer open source. The good news is that the Linux Foundation has introduced OpenTofu, a Terraform fork that’s fully compatible and ready for production use. We highly recommend putting your time and effort into OpenTofu.
8. Argo CD
Argo CD
emerges as a beacon for modern DevOps practices. At its core, it’s a
declarative GitOps continuous delivery tool for Kubernetes, where Git
repositories serve as the source of truth for defining applications and
their environments.
When developers push changes to a repository, Argo CD automatically
detects these updates and synchronizes the changes to the specified
environments, ensuring that the actual state in the cluster matches the
desired state stored in Git, significantly reducing the potential for
human error.
Mastery of Argo CD equips professionals with the ability to manage
complex deployments efficiently at scale. This proficiency leads to
several key benefits, the main one being enhanced automation.
By tying deployments to the version-controlled configuration in Git,
Argo CD ensures consistency across environments. Moreover, it automates
the deployment process, reducing manual errors and freeing up valuable
time for DevOps teams to focus on more strategic tasks.
Furthermore, as applications and infrastructure grow, Argo CD’s
capabilities allow teams to manage deployments across multiple
Kubernetes clusters easily, supporting scalable operations without
compromising control or security.
For professionals in the DevOps field, mastering Argo CD means being
at the forefront of the industry’s move towards more automated,
reliable, and efficient deployment processes. And last but not least,
investing efforts in mastering Argo CD can significantly boost your
career trajectory.
9. Prometheus
Let’s start with a short explanation of what Prometheus is and why it is crucial for DevOps professionals.
Prometheus is an open-source monitoring and alerting toolkit that has
gained widespread adoption for its powerful and dynamic service
monitoring capabilities. At its core, it collects and stores metrics in
real-time as time series data, allowing users to query this data using
its PromQL language.
This capability enables DevOps teams to track everything from CPU
usage and memory to custom metrics that can be defined by the user,
providing insights into the health and performance of their systems.
How does it work? Prometheus works by scraping metrics from
configured targets at specified intervals, evaluating rule expressions,
displaying the results, and triggering alerts if certain conditions are
met. This design makes it exceptionally well-suited for environments
with complex requirements for monitoring and alerting.
Overall, Prometheus is a critical skill for anyone in the DevOps
field. Its ability to provide detailed, real-time insights into system
performance and health makes it indispensable for modern, dynamic
infrastructure management.
As systems become complex, the demand for skilled professionals who
can leverage Prometheus effectively will only increase, making it a key
competency for any DevOps career path.
10. Grafana
Grafana
allows teams to visualize and analyze metrics from various sources,
such as Prometheus, Elasticsearch, Loki, and many others, in
comprehensive, easy-to-understand dashboards.
By transforming this numerical data into visually compelling graphs
and charts, Grafana enables teams to monitor their IT infrastructure and
services, providing real-time insights into application performance,
system health, and more.
But why are Grafana’s skills so crucial in the DevOps field? Above
all, they empower DevOps professionals to keep a vigilant eye on the
system, identifying and addressing issues before they escalate, ensuring
smoother operations and better service reliability.
Moreover, with Grafana, data from various sources can be aggregated
and visualized in a single dashboard, making it a central monitoring
location for all your systems.
On top of that, Grafana’s extensive customization options allow
DevOps professionals to tailor dashboards to their specific needs. This
flexibility is crucial in a field where requirements can vary greatly
from one project to another.
In conclusion, mastering Grafana equips DevOps professionals with the
skills to monitor, analyze, and optimize their systems effectively.
Because of this, the ability to harness Grafana’s power will continue to
be a valuable asset in any DevOps professional’s toolkit.
Conclusion
This list, curated by us, reflects the industry’s best practices and
highlights the essential tools that every DevOps engineer should be
familiar with to achieve professional success in today’s dynamic
technological landscape.
Whether you are a newcomer or an experienced professional looking to
enhance your skills, mastering these tools can significantly boost the
trajectory of your DevOps career.
We’re confident that you might have some valuable additions to make
to this list, and we’re eagerly looking forward to reading your
suggestions in the comments section below. Thanks for sharing your time
with us!
All the popular Linux distributions, such as Ubuntu, Debian, Linux
Mint, Fedora, and Red Hat, keep track of user logins, shutdowns,
restarts, and how long the system is running.
This
information can be very helpful for system administrators when
investigating an incident, troubleshooting problems, or creating a
report of user activity.
In Linux, system and application logs typically reside in the "/var/log/" directory, which can be accessed via the cat or journalctl command. However, there are other commands that use special files managed by the kernel to monitor user activity.
Using Who Command
The who
command in Linux can display user login-related information such as
user account name, user terminal, time when the user logged in, host
name, or IP address from where the user logged in.
$ who
Output:
You can use the -b flag to check the current user login (or last reboot) date and time.
$ who -b
Output:
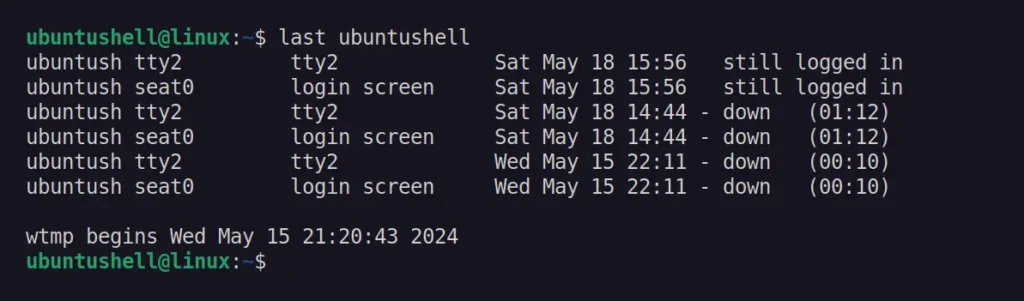
Using Last Command
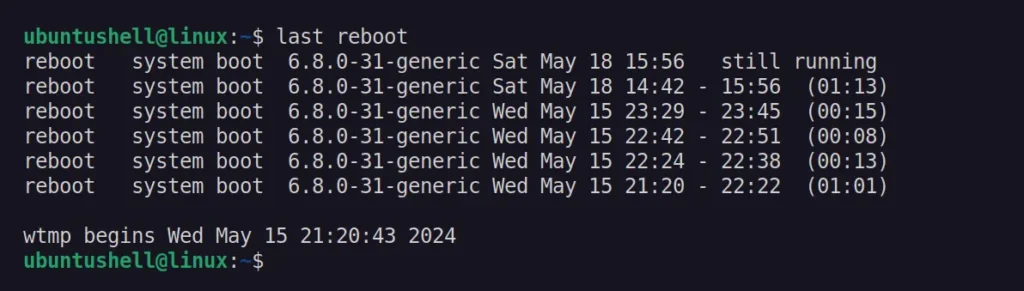
The last command in Linux can display the list of user last logins, their duration, and other information as read from the "/var/log/wtmp" file.
$ last <username>
Output:
Instead of specifying the username, you can substitute it with the reboot parameter to get the time and date of the last reboot in Linux.
The uptime
command in Linux tells how long the system has been running by
displaying the current time, uptime, number of logged-in users, and
average CPU load for the past 1, 5, and 15 minutes.
$ uptime
Output:
Additionally, you can use the -p flag to show only the amount of time the system has been booted for and the -s flag to print the date and time the system booted up at:
$ uptime -p
$ uptime -s
Output:
Using Journalctl COmmand
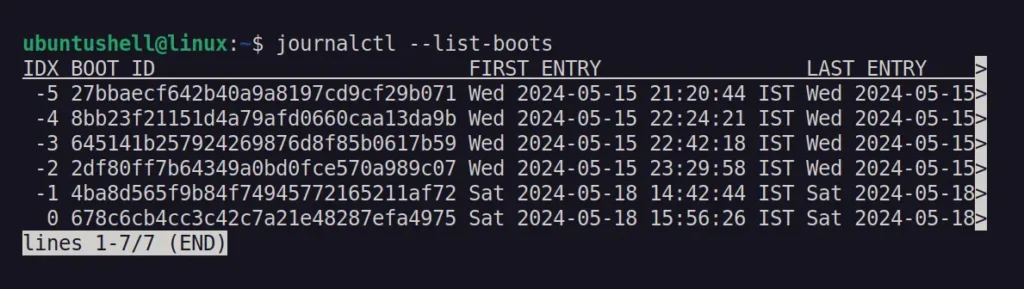
The journalctl
command in Linux is used to query the system journal, which you can use
to display the system logs for more information, such as the number of
times the system has been booted.
$ journalctl --list-boot
Output:
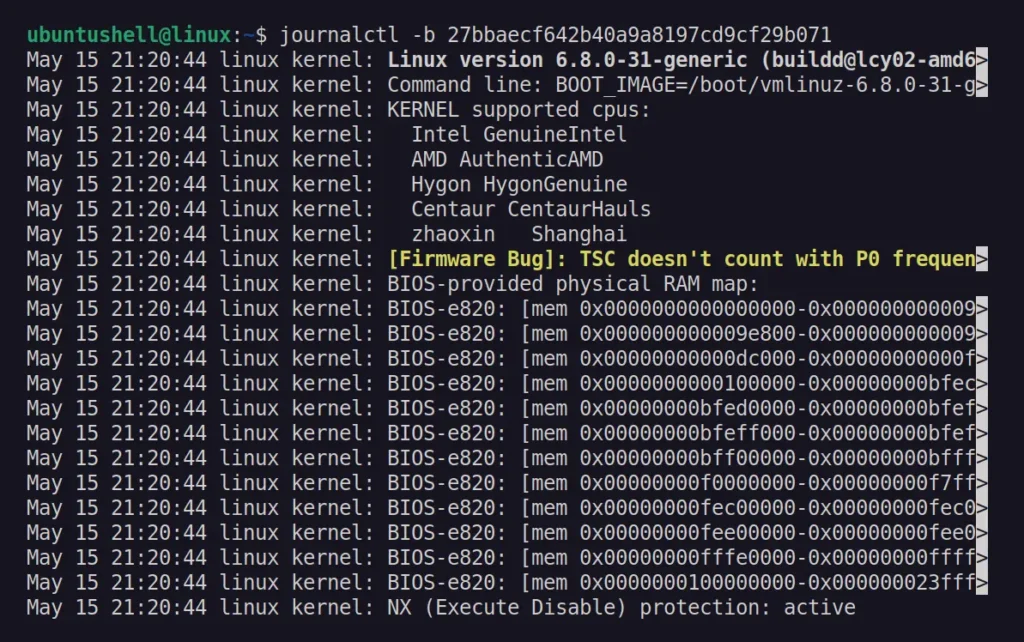
To get more detailed information from the above list of BOOT IDs, you can specify them with the -b flag.
On
a server, it might occur that the desired instance has been shut down
or rebooted unexpectedly. In such cases, you may need to investigate the
cause and find out if anyone is responsible. You can do this using the
following command:
📝 Note
To achieve the same outcome, you can use the last -x command, but I favor this approach as it offers more information.
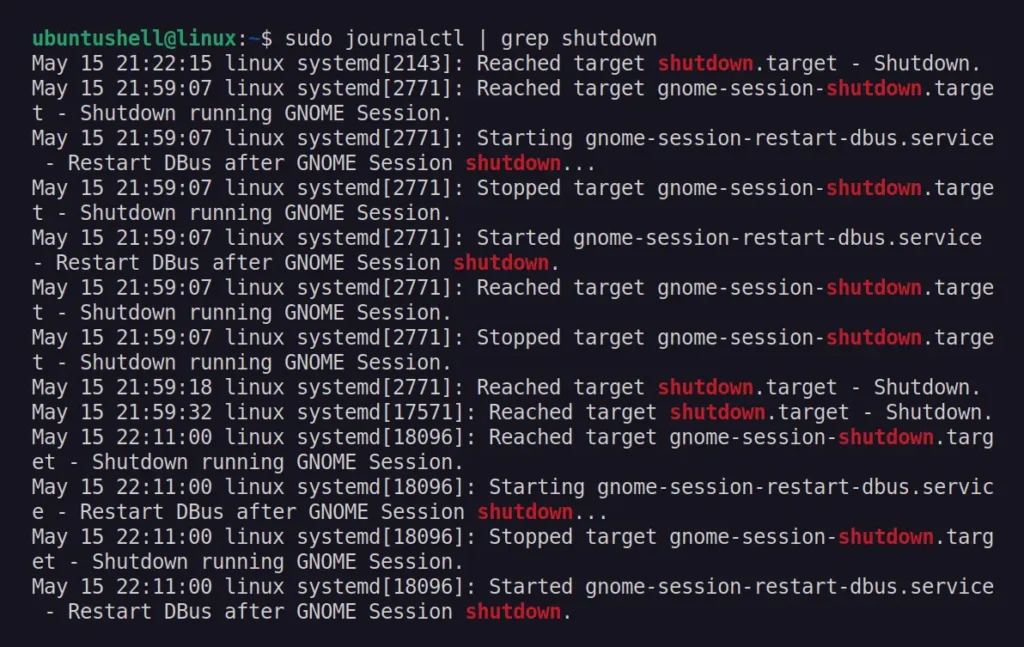
$ sudo journalctl | grep shutdown
Output:
The
first entry in the output above indicates that someone initiated the
shutdown; now you can use the other method explained in this article to
pinpoint the culprit.
Wrap Up
In
this article, you've learned how to check user login, when the system
has been shutdown and rebooted, and who or what is behind it.
direnv is an open-source extension to your current shell for
UNIX-based operating systems like Linux and macOS. It supports hooks for
multiple shell startup files, such as bash, zsh, or fish.
The
main advantage of using direnv is having isolated environment variables
for separate projects. The traditional method was to add all
environment variables inside single shell startup files, which can be ~/.bashrc, ~/.zsh, and config.fish depending upon your Linux shell.
For direnv, you need to create a .envrc
file inside each project directory and populate the project-specific
environment variable. Then it loads and unloads environment variables
depending on the current directory.
Why use Direnv?
Software
developers can use direnv to load 12factor (a methodology for building
software-as-a-service applications) app environment variables such as
your application secrets files for deployment.
How does Direnv work?
Before shell loads a command prompt, direnv checks for the existence of a .envrc or .env
files in your current and parent directories with the appropriate
permissions. Suppose both files are present, then high priority is given
to the .envrc file.
The following file is loaded
into a bash sub-shell, and all variables inside the file are captured by
direnv to make it available to the current Linux shell without user
notice.
Installing Direnv on Linux Systems
The
direnv package is available from the default repositories by installing
it from your current package manager in most Linux distributions, as
shown below.
For Debian, Ubuntu, Mint, PopOS
sudo apt install direnv
For RedHat, Fedora, CentOS
sudo dnf install direnv
For Arch, Manjaro, EndeavourOS
yay -Sy direnv
On other distributions, such as Red Hat or CentOS, you can take advantage of the direnv snaps package, as shown below.
📝 Note
While writing this article, the outdated v2.18.2 of direnv was available on the Snap Store with some issues. #440
sudo snap install direnv
Hook Direnv into your Current Shell
After
the installation, you need to hook up the direnv in your current Linux
shell; it will not work without that. Each shell has its own mechanism
for hooking extensions, such as direnv.
To find out your current shell, execute the following command in your terminal:
echo $0
bash
Follow any of the below-mentioned methods according to your present Linux shell.
For BASH Shell
Append the following line at the end of the ~/.bashrc file:
📝 Note
Make sure it appears above rvm, git-prompt, and other shell extensions that manipulate the prompt.
eval "$(direnv hook bash)"
For ZSH Shell
Append the following line at the end of the ~/.zsh file.
eval "$(direnv hook zsh)"
For Fish Shell
Append the following line at the end of the ~/.config/fish/config.fish file.
eval (direnv hook fish)
Finally, close all the active terminal sessions and source the shell startup files, as shown below.
For BASH Shell
source ~/.bashrc
For ZSH Shell
source ~/.zshrc
For Fish SHELL
source ~/.config/fish/config.fish
How to Use Direnv
Let
us see the practical usage of direnv. First, we will create a new
directory on our current path for demo purposes with the name ubuntushell_project and move into it.
mkdir ubuntushell_project
cd ubuntushell_project/
Let’s check if the $TEST_VARIABLE variable is available on the current project path or not using the echo command as shown below.
echo $TEST_VARIABLE
Nope
Above, instead of a blank space, I replaced it with "nope", which means there is no global or local environment variable available for $TEST_VARIABLE.
Next, we will create a new file in the current project directory (referring to ubuntushell_project) with the .envrc name and add $TEST_VARIABLE inside the file using the echo command, as shown below.
echo export TEST_VARIABLE=ubuntushell > .envrc
direnv: loading ~/etw/.envrc
direnv: export +TEST_VARIABLE
By default, the .envrc file is blocked. Therefore, we need to run the direnv allow . command to unblock and allow to load the .envrc content in our Linux shell, as shown below.
direnv allow .
Let's recheck the $TEST_VARIABLE output as shown below.
echo $TEST_VARIABLE
ubuntushell
Below is the behavior of the above command.
Tada! We have successfully created a .envrc file and loaded the file’s content inside our shell using the direnv command.
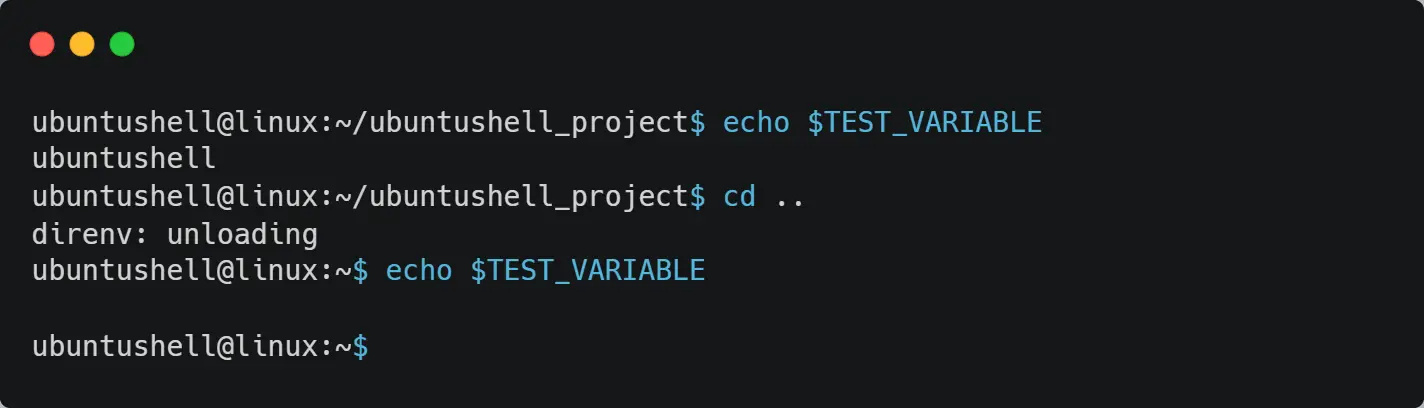
If you take one step back to get out of the current working directory (referring to ubuntushell_project) and execute the echo command for $TEST_VARIABLE, you will find the content is blank.
echo $TEST_VARIABLE
Nope
Below is the behavior of the above command.
Now that you re-enter the ubuntushell_project directory, the .envrc file will be loaded in your bash shell with its contents inside it.
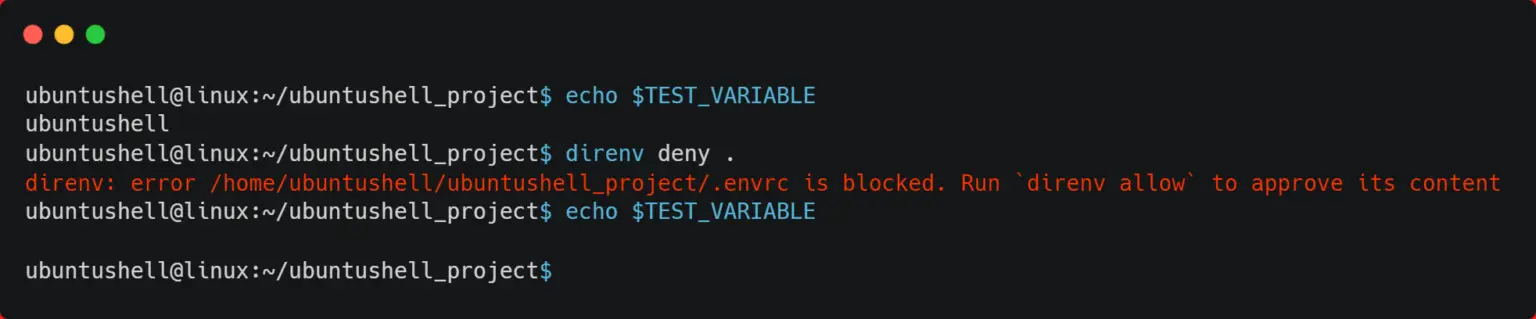
To revoke the authorization of the .envrc file and disallow content to be loaded into your current Linux shell, execute the below command.
direnv deny .
Below is the behavior of the above command.
Remove Direnv
Suppose
you don’t like direnv and want to remove it from your Linux system.
Then use the below command to remove direnv from your system.
For Debian, Ubuntu, Mint, PopOS
sudo apt purge direnv
For RedHat, Fedora, CentOS
sudo dnf remove direnv
For Arch, Manjaro, EndeavourOS
yay -Rs direnv
Final Word
Since you now understand how the direnv command works, you can follow the above steps to create an isolated environment for a specific project on the Linux system.
Jq
is a powerful and highly flexible parser program that can stream and
filter JSON data out of files and UNIX pipes. This article will teach
you the basics of jq, present code examples, as well as some alternative
implementations that you can install today.
The most common use for jq is for processing and manipulating JSON
responses from Software-as-a-Service (SaaS) APIs. For instance, you can
use jq along with cURL to tap into Digitalocean’s API endpoints to get
your account details.
Aside from that, jq is also a powerful utility for managing large
JSON files. Some of the most popular database programs today such as
MongoDB, PostgreSQL, and MySQL support JSON as a way to store data. As
such, learning jq gives you an edge in understanding how those database
systems work.
To start with jq, install its binary package to your system:
sudoaptinstall jq
Find an open API endpoint that you can test jq on. In my case, I’m going to use the ipinfo.io’s IP checker API.
The most basic filter for jq is the dot (.) filter. This will pretty print the JSON response as jq received it from its standard input:
curl https://ipinfo.io/| jq '.'
Another basic filter is the pipe (|) symbol. This is a special filter
that passes the output of one filter as the input of another:
curl https://ipinfo.io/| jq '. | .ip'
The value after the pipe operator is the “Object Identifier-Index.”
This searches your JSON input for any variable that matches its text and
prints its value on the terminal. In this case, I’m looking for the
value of the “ip:” key.
With the basics done and dusted, the following sections will show you some of the tricks that you can do using jq.
Most modern websites today offer open API endpoints for reading data
inside their platforms. For example, every Github repository has its own
API URL for you to retrieve the latest commits and issues for that
project.
You can use an API endpoint like this with jq to create your own
simple “RSS-like” feed. To start, use cURL to test if the endpoint is
working properly:
This will show the different fields that the Github API sends to jq.
You can use these to create your own custom JSON object by piping the
input to the curly braces ({}) filter:
You can also create a small Bash script to display the latest issues
from your favorite Github project. Paste the following block of code
inside an empty shell script file:
Save your file, then run the following command to make it executable:
chmod u+x ./script.sh
Test your new feed reader by listing the latest issue in your favorite Github repo:
./script.sh 0
2. Reading and Searching through a JSON Database
Aside from reading data off of APIs, you can also use jq to manage
JSON files in your local machine. Start by creating a simple JSON
database file using your favorite text editor:
nano ./database.json
Paste the following block of data inside your file, then save it:
Test whether jq reads your JSON file properly by printing the first object in your database array:
jq '.[0]' database.json
Make a query on your JSON database using the “Object
Identifier-Index” filter. In my case, I am searching for the value of
the “.name” key on every entry in my database:
jq '.[] | .name' database.json
You can also use some of jq’s built-in functions to filter your
queries based on certain qualities. For example, you can search for and
print all the JSON objects that have a “.name” value with more than six
characters:
jq '.[] | select((.name|length)>6)' database.json
Operating on JSON Databases with jq
In addition to that, jq can operate on JSON databases similar to a
basic spreadsheet. For instance, the following command prints the sum
total of the “.balance” key for every object in the database:
jq '[.[] | .balance] | add' database.json
You can even extend this by adding a conditional statement to your
query. The following will only add the “.balance” if the “.name” value
of the second object is “Alice”:
jq 'if .[1].name == "Alice" then [ .[] | .balance ] | add else "Second name is not Alice" end' database.json
It’s possible to temporarily remove variables from your JSON
database. This can be useful if you’re testing your filter and you want
to make sure that it can still process your dataset:
jq 'del(.[1].name) | .[]' database.json
You can also insert new variables to your database using the “+”
operator. For example, the following line adds the variable “active:
true” to the first object in the database:
jq '.[0] + {active: true}' database.json
Note: You can make your changes permanent by piping the output of your jq command to your original database file: jq '.[0] + {active: true}' database.json > database.json.
3. Transforming Non-JSON Data in jq
Another brilliant feature of jq is that it can accept and work with
non-JSON data. To achieve that, the program uses an alternative “slurp
mode” where it converts any space and newline delimited data into a JSON
array.
You can enable this feature by piping data into jq with an -s flag:
echo'1 2'| jq -s .
One advantage of converting your raw data into an array is that you
can address them using array index numbers. The following command adds
two values by referring to their converted array location:
echo'1 2'| jq -s'.[0] + .[1]'
You can take this array location further and construct new JSON code
around it. For instance, this code converts the text from the echo
command to a JSON object through the curly braces filter:
Apart from taking in raw data, jq can also return non-JSON data as
its output. This is useful if you’re using jq as part of a larger shell
script and you only need the result from its filters.
To do that, run jq followed by the -r flag. For example, the following command reads all the names from my database file and returns it as plain text data:
jq -r'.[] | .name' database.json
Alternative JSON Parsers to jq
Since the code for jq is open source, various developers have created
their own versions of the JSON parser. Each of these has its own unique
selling point that either improves on or changes a core part of jq.
1. jaq
Jaq is a powerful JSON parser that provides a near identical feature set to jq.
Written in Rust, one of the biggest selling points of Jaq is that it
can run the jq language up to 30 times faster than the original parser
while still retaining backward compatibility. This alone makes it
valuable when you’re running large jq filters and you want to maximize
the performance out of your machine.
That said, one downside of jaq is that it’s not currently available
on Debian, Ubuntu, and Fedora repositories. The only way to obtain it is
to either download Homebrew or compile it from source.
2. gojq
Gojq
is an alternative JSON parser that’s written entirely in Go. It
provides an accessible and easy-to-use version of jq that you can
install on almost any platform.
The original jq program can be incredibly terse in its error
messages. As a result, debugging jq scripts is especially hard for a new
jq user. Gojq solves this issue by showing you where the mistake is in
your script as well as providing detailed messages on the kind of error
that happened.
Another selling point of gojq is that it can read and process both
JSON and YAML files. This can be especially helpful if you’re a Docker
and Docker Compose user and you want to automate your deployment
workflow.
Gojq’s biggest issue is that it removed some of the features that
come by default on the original jq parser. For instance, options such as
--ascii-output, --seq, and --sort-keys doesn’t exist on gojq.
Unlike jaq and gojq, fq
is a comprehensive software toolkit that can parse both text and binary
data. It can work with a variety of popular formats such as JSON, YAML,
HTML, and even FLAC.
The biggest feature of fq is that it contains a built-in hex reader
for files. This makes it trivial to look at a file’s internal structure
to determine how it’s made and whether there’s anything wrong with it.
Aside from that, fq also uses the same syntax for jq when dealing with
text which makes it easy to learn for anyone already familiar with jq.
One downside of this ambitious goal is that fq is still under heavy
development. As such, some of the program’s features and behaviors are
still subject to sweeping changes.
Exploring jq, how it works, and what makes it special is just the
first step in learning how to make programs on your computer. Take a
deep dive into the wonderful world of coding by reading the basics of shell programming.