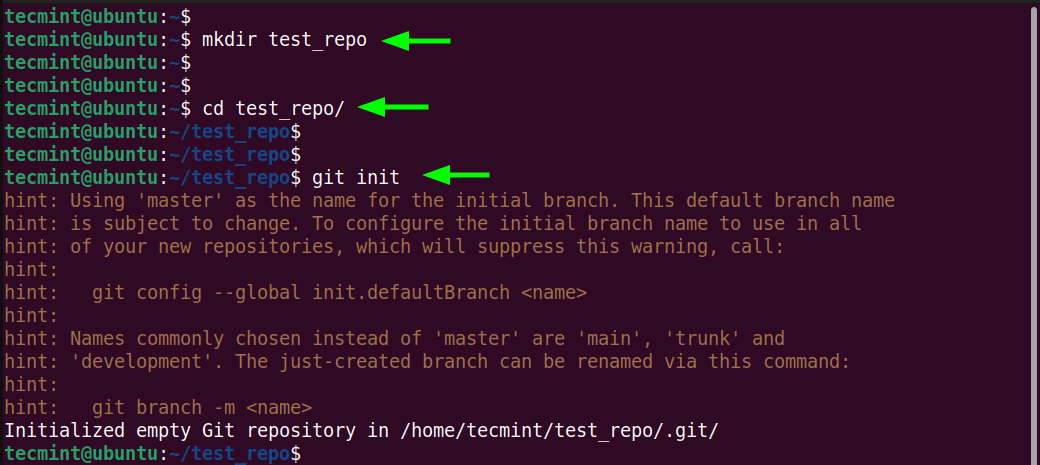
How to Use awk to Perform Arithmetic Operations in Loops
The awk command
is a powerful tool in Linux for processing and analyzing text files,
which is particularly useful when you need to perform arithmetic
operations within loops.
This article will guide you through using awk for arithmetic operations in loops, using simple examples to make the concepts clear.
What is awk?
awk is a scripting language designed for text
processing and data extraction, which reads input line by line, splits
each line into fields, and allows you to perform operations on those
fields. It’s commonly used for tasks like pattern matching, arithmetic
calculations, and generating formatted reports.
BEGIN: Code block executed before processing the input.
actions: Code block executed for each line of the input.
END: Code block executed after processing all lines.
Performing Arithmetic Operations in Loops
Let’s explore how to use awk to perform arithmetic operations within loops with the following useful examples to demonstrate key concepts.
Example 1: Calculating the Sum of Numbers
Suppose you have a file named numbers.txt containing the following numbers:
5
10
15
20
You can calculate the sum of these numbers using awk:
awk '{ sum += $1 } END { print "Total Sum:", sum }' numbers.txt
Explanation:
{ sum += $1 }: For each line, the value of the first field $1 is added to the variable sum.
END { print "Total Sum:", sum }: After processing all lines, the total sum is printed.
Number Sum Calculation
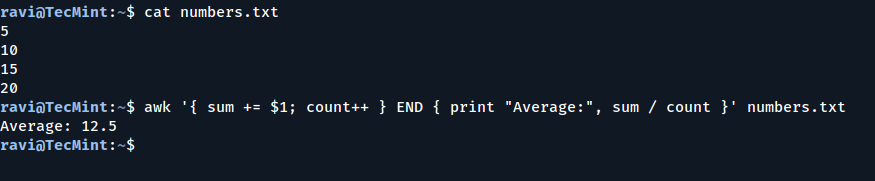
Example 2: Calculating the Average
To calculate the average of the numbers:
awk '{ sum += $1; count++ } END { print "Average:", sum / count }' numbers.txt
Explanation:
count++: Increments the counter for each line.
sum / count: Divides the total sum by the count to calculate the average.
Calculate the Average of a Set of Numbers
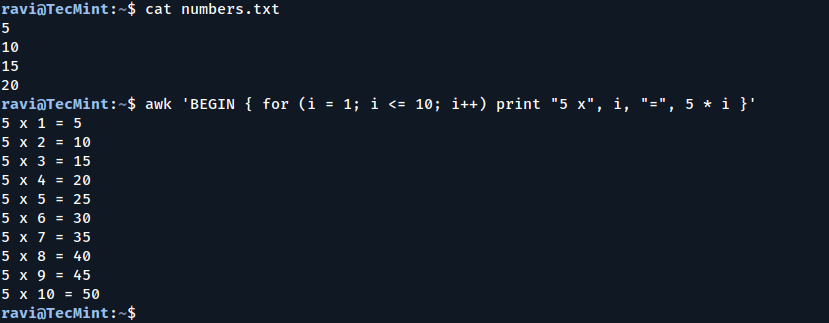
Example 3: Multiplication Table
You can use awk to generate a multiplication table for a given number. For example, to generate a table for 5:
awk 'BEGIN { for (i = 1; i <= 10; i++) print "5 x", i, "=", 5 * i }'
Explanation:
for (i = 1; i <= 10; i++): A loop that runs from 1 to 10.
print "5 x", i, "=", 5 * i: Prints the multiplication table.
Multiplication table with awk
Example 4: Factorial Calculation
To calculate the factorial of a number (e.g., 5):
awk 'BEGIN { n = 5; factorial = 1; for (i = 1; i <= n; i++) factorial *= i; print "Factorial of", n, "is", factorial }'
Explanation:
n = 5: The number for which the factorial is calculated.
factorial *= i: Multiplies the current value of factorial by i in each iteration.
Factorial Calculation Example
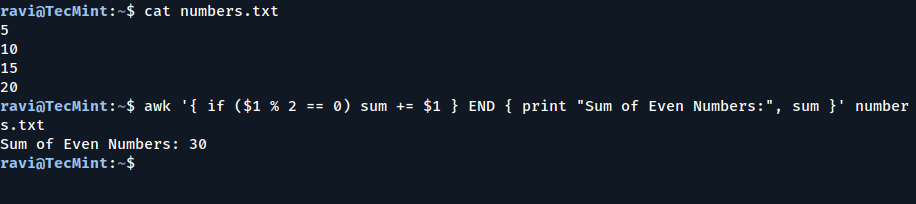
Example 5: Summing Even Numbers
To sum only the even numbers from a file:
awk '{ if ($1 % 2 == 0) sum += $1 } END { print "Sum of Even Numbers:", sum }' numbers.txt
Explanation:
if ($1 % 2 == 0): Checks if the number is even.
sum += $1: Adds the even number to the sum.
Calculate the Sum of Even Numbers
Conclusion
The awk command is a versatile tool for performing
arithmetic operations in loops. By combining loops, conditions, and
arithmetic operators, you can handle a wide range of tasks efficiently.
Practice these examples and experiment with your own scripts to unlock the full potential of awk!
Kill a Process Running on a Specific Port in Linux (via 4 Methods)
A newbie user often struggles to identify the process behind a
specific listening port. Indeed, it’s not all their fault, as some
listening ports are started and managed by the OS. However, they may
forget the name or struggle to find the process ID of the service they
manually started.
The
running (or unresponsive) process must be stopped to free the occupied
port and make it available for other processes. Let’s assume you are
running an Apache server that uses ports 80 (for HTTP) and 443 (for
HTTPS). You won’t be able to launch an Nginx server that shares these
common ports until the Apache server is stopped.
It’s one of the
many scenarios, and listening ports are often overlooked by users until a
process fails to launch due to port unavailability. Hence, in this
quick guide, I’ll show you how to identify and kill a process running on
a specific port in Linux.
How to Kill a Process Running on a Specific Port in Linux
There
are many ways to find and terminate processes running on a certain
port. However, IT Guy, SysAdmin, or network engineers often favor using
the CLI tool for this job. In such cases, you can use the “killport“, “fuser“, “lsof“, “netstat“, and “ss” commands as detailed in the following sections.
Method 1: Kill a Process Running on a Specific Port Using killport
Killport
is a fantastic CLI tool for killing a process running on a specific
port by using only the port number, without needing a service name or
process ID. The only inconvenience is that it’s an external tool, but
you can quickly install it on your Linux system by following our installation guide.
Once
you have it installed, you can quickly terminate the process running on
a certain port. Let’s assume you have an Apache server running on port
80. To stop it, simply execute this command:
$ sudo killport 80
Output:
Well, ignore the last “No such process”
message—it’s simply the response to the last kill signal sent to the
process. The key point is that the port is now available for use by any
other process.
Method 2: Kill a Process Running on a Specific Port Using fuser
Fuser
is another great tool used for identifying processes using specific
files, file systems, or sockets. Despite using it to identify processes
running on specific sockets (or ports), you can use it to troubleshoot
issues related to file locking, process management, and system
resources.
It comes preinstalled on some popular Linux
distributions like Ubuntu, Fedora, and Manjaro, but if it’s not
available on your system, you can install the “psmisc” package that contains “fuser” and other command-line utilities.
# On Debian, Ubuntu, Kali Linux, Linux Mint, Zorin OS, Pop!_OS, etc.
$ sudo apt install psmisc
# On Red Hat, Fedora, CentOS, Rocky Linux, AlmaLinux, etc.
$ sudo dnf install psmisc
# On Arch Linux, Manjaro, BlackArch, Garuda, etc.
$ sudo pacman -S psmisc
# On OpenSUSE system
$ sudo zypper install psmisc
To find out the process running on a specific port, you can specify the port number and its TCP or UDP protocol in the “fuser” command.
$ sudo fuser 80/tcp
The above command will return the process ID in charge of handling the specified port.
Instead of printing the running process ID, you can use the “-k” option with the above command to terminate the process associated with that process ID.
$ sudo fuser -k 80/tcp
Output:
Once
you terminate the process with this method, you may need to wait a
60-second delay before the process fully shuts down. This is implemented
as a security measure to avoid potential data corruption or conflicts.
If you want to immediately stop the running process, you can specify the
process ID in the “sudo kill -9 <PID>” command.
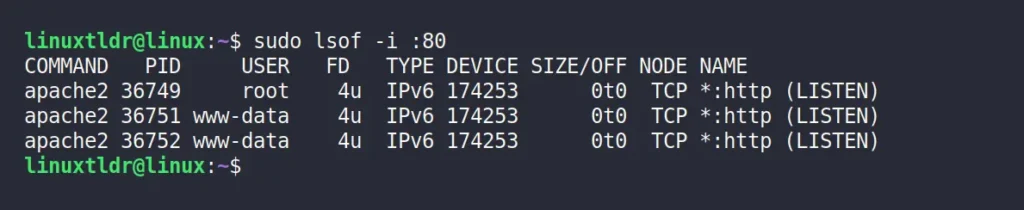
Method 3: Kill a Process Running on a Specific Port Using lsof
Lsof
is another powerful tool used to identify the process responsible for
managing specific files, directories, network sockets, and other system
resources on the active system. It comes pre-installed with nearly all
Linux distributions, requiring no additional installation.
To
identify the process name and ID associated with a specific port, use
the following command, followed by the port number you wish to check:
$ sudo lsof -i :80
The above command will return the output in multiple columns, with your focus areas being solely the “COMMAND” and “PID” columns.
Once you have the process ID, you can use the “kill” command to terminate the process.
$ sudo kill -9 36749 36751 36752
Output:
The “-9” option sends the “SIGKILL” signal to aggressively terminate the process, while you can alternatively use the “-1” option to hang up the process (less secure) and the “-15” option to gently kill the process (default).
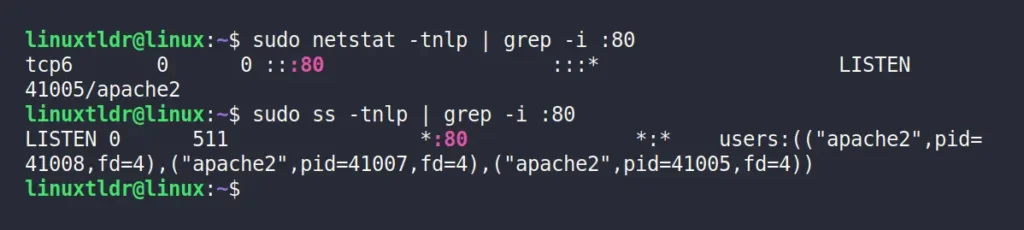
Method 4: Kill a Process Running on a Specific Port Using netstat and ss
Netstat
and ss are among the most widely used tools for SysAdmins to quickly
pinpoint a process name and process ID associated with a specific port.
However, netstat is considered depricated, and some major Linux
distributions have removed it, requiring the installation of the “net-tools” package for usage.
The ss command
can be found in most Linux systems, and it’s basically an improved
version of netstat. Both tools use almost identical command syntaxes,
with the “-tnlp” option being the most common to identify the listening port’s process name and process ID, where each option follows.
“-t“: Shows the TCP sockets
“-n“: Avoid resolving the service names
“-l“: Show the listening sockets
“-p“: Show the process ID and name
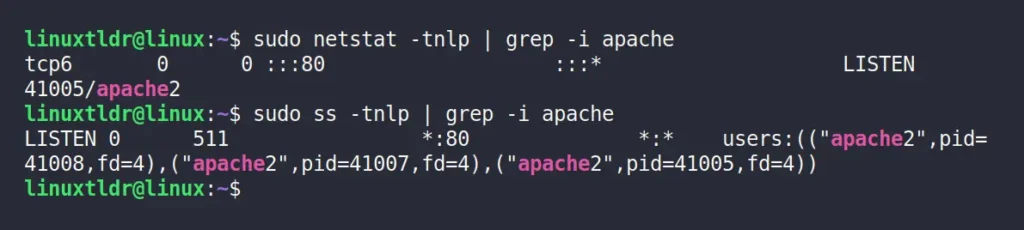
To find out the process name or ID of port 80, you can use either the netstat or ss command with the “-tnlp” option, along with the grep command, to filter out the data for only the specified port number.
Finally, to kill the corresponding process, you can specify its process ID with the following command:
$ sudo kill -9 41005
Output:
When terminating the process using the “kill -p”
command, ensure that the service is not actively being used by any
other process, as forcefully terminating it could lead to data
corruption or loss.
Final Word
In
this article, you learned different ways to terminate a process running
on a specific port that would work for almost all major Linux
distributions, such as Debian, Ubuntu, Red Hat, Fedora, Arch, Manjaro,
etc. Well, if you have any questions or queries, feel free to tell us in
the comment section.
Setting Up a Development Environment for Python, Node.js, and Java on Fedora
Fedora is a popular Linux distribution known for its cutting-edge features and stability, making it an excellent choice for setting up a development environment.
This tutorial will guide you through setting up a development environment for three widely-used programming languages: Python, Node.js, and Java. We will cover the installation process, configuration, and common tools for each language.
Prerequisites
Before we begin, ensure you have a working installation of Fedora.
You should have administrative (root) access to the system, as
installing software requires superuser privileges.
If you’re using a non-root user, you can use sudo for commands requiring administrative rights.
Step 1: Setting Up Python Development Environment in Fedora
Python is one of the most popular programming
languages, known for its simplicity and versatility. Here’s how you can
set up a Python development environment on Fedora.
1.1 Install Python in Fedora
Fedora comes with Python
pre-installed, but it’s always a good idea to ensure you have the
latest version. You can check the current version of Python by running:
python3 --version
To install the latest version of Python, run the following command:
sudo dnf install python3 -y
1.2 Install pip (Python Package Installer)
pip is a package manager for Python, and it’s essential for installing third-party libraries.
sudo dnf install python3-pip -y
Verify the installation by running:
pip3 --version
1.3 Set Up a Virtual Environment
A virtual environment allows you to create isolated Python
environments for different projects, ensuring that dependencies don’t
conflict.
To set up a virtual environment, run the following commands.
To deactivate the virtual environment, simply run:
deactivate
1.4 Install Essential Python Libraries
To make development easier, you may want to install some essential Python libraries.
pip install numpy pandas requests flask django
1.5 Install an Integrated Development Environment (IDE)
While you can use any text editor for Python, an IDE like PyCharm or Visual Studio Code (VSCode) can provide advanced features like code completion and debugging.
Alternatively, you can download PyCharm from the official website.
Step 2: Setting Up Node.js Development Environment in Fedora
Node.js is a popular runtime for building server-side applications with JavaScript and here’s how to set up Node.js on Fedora.
2.1 Install Node.js in Fedora
Fedora provides the latest stable version of Node.js in its official repositories.
sudo dnf install nodejs -y
You can verify the installation by checking the version.
node --version
2.2 Install npm (Node Package Manager) in Fedora
npm is the default package manager for Node.js and is used to install and manage JavaScript libraries. It should be installed automatically with Node.js, but you can check the version by running:
npm --version
2.3 Set Up a Node.js Project in Fedora
To start a new Node.js project, create a new directory for your project.
mkdir my-node-project
cd my-node-project
Next, initialize a new Node.js project, which will create a package.json file, which will contain metadata about your project and its dependencies.
npm init
Install dependencies. For example, to install the popular express framework, run:
npm install express --save
Create a simple Node.js application in index.js.
const express = require('express');
const app = express();
const port = 3000;
app.get('/', (req, res) => {
res.send('Hello World!');
});
app.listen(port, () => {
console.log(`Server is running at http://localhost:${port}`);
});
Run the application.
node index.js
2.4 Install an IDE or Text Editor
For Node.js development, Visual Studio Code (VSCode) is a great option, as it provides excellent support for JavaScript and Node.js.
sudo dnf install code -y
Alternatively, you can use Sublime Text.
Step 3: Setting Up Java Development Environment in Fedora
Java is one of the most widely used programming languages, especially for large-scale applications.
Here’s how to set up Java on Fedora.
3.1 Install OpenJDK in Fedora
Fedora provides the OpenJDK package, which is an open-source implementation of the Java Platform.
sudo dnf install java-17-openjdk-devel -y
You can verify the installation by checking the version.
java -version
3.2 Set Up JAVA_HOME Environment Variable in Fedora
To ensure that Java is available system-wide, set the JAVA_HOME environment variable.
First, find the path of the installed Java version:
sudo update-alternatives --config java
Once you have the Java path, add it to your .bashrc file.
In this tutorial, we’ve covered how to set up development environments for Python, Node.js, and Java on Fedora. We also touched on setting up essential tools like Git, Docker, and databases to enhance your development workflow.
With these steps, you can begin developing applications in any of
these languages, leveraging Fedora’s powerful development tools.
When you’re writing code in Python, it’s important
to make sure that your code works as expected. One of the best ways to
do this is by using unit tests, which help you check if small parts (or
units) of your code are working correctly.
In this article, we will learn how to write and run effective unit tests in Python using PyTest, one of the most popular testing frameworks for Python.
What are Unit Tests?
Unit tests are small, simple tests that focus on checking a single
function or a small piece of code. They help ensure that your code works
as expected and can catch bugs early.
Unit tests can be written for different parts of your code, such as
functions, methods, and even classes. By writing unit tests, you can
test your code without running the entire program.
Why Use PyTest?
PyTest is a popular testing framework for Python that makes it easy to write and run tests.
It’s simple to use and has many useful features like:
It allows you to write simple and clear test cases.
It provides advanced features like fixtures, parameterized tests, and plugins.
It works well with other testing tools and libraries.
It generates easy-to-read test results and reports.
Setting Up PyTest in Linux
Before we start writing tests, we need to install PyTest. If you don’t have PyTest installed, you can install it using the Python package manager called pip.
pip install pytest
Once PyTest is installed, you’re ready to start writing tests!
Writing Your First Test with PyTest
Let’s start by writing a simple function and then write a test for it.
Step 1: Write a Simple Function
First, let’s create a Python function that we want to test. Let’s say we have a function that adds two numbers:
# add.py
def add(a, b):
return a + b
This is a simple function that takes two numbers a and b, adds them together, and returns the result.
Step 2: Write a Test for the Function
Now, let’s write a test for the add function. In PyTest, tests are written in separate files, typically named test_*.py to make it easy to identify test files.
Create a new file called test_add.py and write the following test code:
We define a test function called test_add_numbers(). In PyTest, a test function should start with the word test_.
Inside the test function, we use the assert statement to check if the result of calling the add function matches the expected value. If the condition in the assert statement is True, the test passes; otherwise, it fails.
Step 3: Run the Test
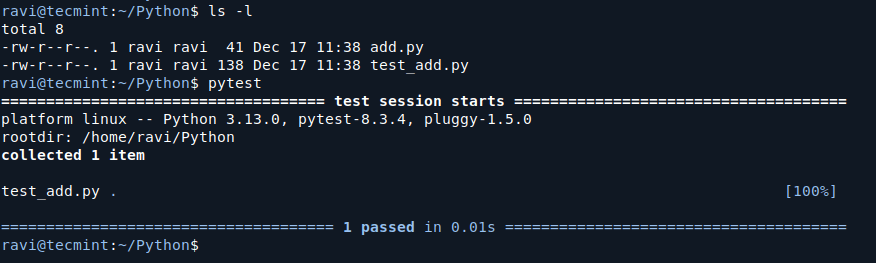
To run the test, open your terminal and navigate to the directory where your test_add.py file is located and then run the following command:
pytest
PyTest will automatically find all the test files (those that start with test_) and run the tests inside them. If everything is working correctly, you should see an output like this:
Verifying Python Code Functionality
The dot (.) indicates that the test passed. If there were any issues, PyTest would show an error message.
Writing More Advanced Tests
Now that we know how to write and run a basic test, let’s explore some more advanced features of PyTest.
Testing for Expected Exceptions
Sometimes, you want to test if your code raises the correct exceptions when something goes wrong. You can do this with the pytest.raises() function.
Let’s say we want to test a function that divides two numbers. We
want to raise an exception if the second number is zero (to avoid
division by zero errors).
Here’s the divide function:
# divide.py
def divide(a, b):
if b == 0:
raise ValueError("Cannot divide by zero")
return a / b
Now, let’s write a test for this function that checks if the ValueError is raised when we try to divide by zero:
We added a new test function called test_divide_by_zero().
Inside this function, we use pytest.raises(ValueError) to check if a ValueError is raised when we call the divide function with zero as the second argument.
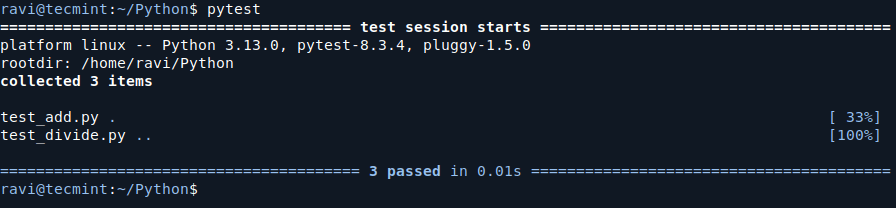
Run the tests again with the pytest command. If everything is working correctly, you should see this output:
Test Your Code with PyTest
Using Fixtures for Setup and Cleanup
In some cases, you may need to set up certain conditions before running your tests or clean up after the tests are done. PyTest provides fixtures to handle this.
A fixture is a function that you can use to set up or tear down
conditions for your tests. Fixtures are often used to create objects or
connect to databases that are needed for the tests.
Here’s an example of using a fixture to set up a temporary directory for testing file operations:
# test_file_operations.py
import pytest
import os
@pytest.fixture
def temporary_directory():
temp_dir = "temp_dir"
os.mkdir(temp_dir)
yield temp_dir # This is where the test will run
os.rmdir(temp_dir) # Cleanup after the test
def test_create_file(temporary_directory):
file_path = os.path.join(temporary_directory, "test_file.txt")
with open(file_path, "w") as f:
f.write("Hello, world!")
assert os.path.exists(file_path)
Explanation of the code:
We define a fixture called temporary_directory that creates a temporary directory before the test and deletes it afterward.
The test function test_create_file() uses this fixture to create a file in the temporary directory and checks if the file exists.
Run the tests again with the pytest command. PyTest will automatically detect and use the fixture.
Parameterize Your Tests with Pytest
Sometimes, you want to run the same test with different inputs. PyTest allows you to do this easily using parametrize.
Let’s say we want to test our add function with several pairs of numbers. Instead of writing separate test functions for each pair, we can use pytest.mark.parametrize to run the same test with different inputs.
We use the pytest.mark.parametrize decorator to define multiple sets of inputs (a, b, and expected).
The test function test_add_numbers() will run once for each set of inputs.
Run the tests again with the pytest command, which will run the test four times, once for each set of inputs.
Conclusion
In this article, we’ve learned how to write and run effective unit tests in Python using PyTest to catch bugs early and ensure that your code works as expected.
PyTest makes it easy to write and run these tests,
and with its powerful features, you can handle more complex testing
needs as you grow in your Python journey.
Basics of Pandas: 10 Core Commands for Data Analysis
Pandas is a popular and widely-used Python
library used for data manipulation and analysis, as it provides tools
for working with structured data, like tables and time series, making it
an essential tool for data preprocessing.
Whether you’re cleaning data, looking at datasets, or getting data ready for machine learning, Pandas is your go-to library. This article introduces the basics of Pandas and explores 10 essential commands for beginners.
What is Pandas?
Pandas is an open-source Python library designed for data manipulation and analysis, which is built on top of NumPy, another Python library for numerical computing.
Pandas introduces two main data structures:
Series: A one-dimensional labeled array capable of holding any data type (e.g., integers, strings, floats).
DataFrame: A two-dimensional labeled data structure, similar to a spreadsheet or SQL table, where data is organized in rows and columns.
These operations allow you to combine datasets for a comprehensive analysis.
10. Exporting Data
After processing your data, you may need to save it using the to_csv() function:
data.to_csv('processed_data.csv', index=False)
This command saves the DataFrame to a CSV file without the index
column. You can also export to other formats like Excel, JSON, or SQL.
Conclusion
Pandas is an indispensable tool for data preprocessing, offering a wide range of functions to manipulate and analyze data.
The 10 commands covered in this article provide a solid foundation
for beginners to start working with Pandas. As you practice and explore
more, you’ll discover the full potential of this powerful library.
To avoid any confusion, I must first state that this article is dealing with the man and tldr commands in Linux. While man pages
are incredibly detailed, they can be intimidating, especially for those
just starting out. Instead, you can use the tldr command to get a
short, simple, and easy-to-understand explanation of any Linux command.
In this guide, we’ll dive deep into what tldr is, how to use it, and why it’s a better alternative to the traditional man command.
The man command, referred to manual, is the traditional
way to access documentation for commands in Unix-like operating systems.
When you type man along with a command, it pulls up the
manual page for that specific command, providing detailed information
about its usage, options, and examples.
For example, you can get a detailed overview of the ls command by executing this:
manls
This opens a manual page listing all the available options. The information is organized into sections like NAME, SYNOPSIS, DESCRIPTION, OPTIONS, and EXAMPLES. While this structure makes it easy to navigate, it can also be quite extensive.
The man command can be incredibly useful for advanced
users who need in-depth knowledge, but it may feel like wading through a
vast amount of text for beginners or even intermediate users. The sheer
volume of information can overwhelm you, and you can easily lose your
way in it.
What Is Tldr?
tldr stands for too long; didn’t read,
a phrase originating on the internet to describe a summary of a long
text piece. Unlike man pages, tldr pages focus on the most useful
options and provide clear, real-world examples.
For example, when you run tldr ls in the terminal, the tldr command will provide you with a brief overview of the ls command, along with some of its most commonly used options:
tldr ls
As you can see, tldr pages are much more concise and to the point, making it easier for new users to quickly understand and start using a command.
How to Use Tldr
To access tldr pages conveniently, install a supported client. One of
the main clients is Node.js, which serves as the original client for
the tldr project. To explore other client applications available for
different platforms, you can refer to the TLDR clients wiki page.
You can install Node.js using the package manager corresponding to
your Linux distribution. For example, on Debian-based distributions such
as Linux Mint or Ubuntu, run this:
sudoaptinstall nodejs npm
Once you’ve installed Node.js and its package manager npm, you can globally install the tldr client by running this:
sudo npm install-g tldr
If you prefer, you can also install tldr as a Snap package by executing:
sudo snap install tldr
After installation, the tldr client allows you to view simplified,
easy-to-understand versions of command-line manual pages. For instance,
to get a concise summary of the tar command, simply type:
tldr tar
You can also search for specific commands using keywords with the --search option:
tldr --search"Keyword"
Additionally, you can list all available commands using the -l option:
tldr -l
You can also simply run tldr in the terminal to explore all other tldr command options:
If you prefer a browser-based experience, the official tldr website
offers the same content in a web-friendly format. It includes features
like a search bar with autocomplete and labels indicating whether a
command is specific to Linux or macOS.
Building modern apps can seem overwhelming with the many tools and
technologies available. However, having the right tools can make a huge
difference in the development process, helping developers work faster
and more efficiently.
Whether you’re making a mobile application, a web application, or a
desktop application, there are essential tools that can improve your
workflow. This article will cover some must-have developer tools for
building modern apps and explain how they can help you.
1. Code Editors and IDEs (Integrated Development Environments)
The foundation of any development work is the code editor or Integrated Development Environment (IDE) you use. A good code editor is essential for writing and editing your app’s code efficiently.
Visual Studio Code (VS Code)
Visual Studio Code is a free, open-source code editor developed by Microsoft that supports a variety of programming languages, offers a rich set of extensions, and has features like IntelliSense, debugging, and version control.
Visual Studio Code
JetBrains IntelliJ IDEA
IntelliJ IDEA
is a powerful IDE that’s especially good for Java development, though
it supports many other languages and comes with smart code suggestions
and easy refactoring tools.
IntelliJ IDEA: A Powerful IDE
Sublime Text
Sublime Text
is a lightweight code editor with a clean interface, ideal for quick
edits or smaller projects, that also supports extensions and
customizable features.
Sublime Text: A Versatile Code Editor
Vim Editor
Vim, short for “Vi Improved“, is a powerful, open-source text editor designed for both command-line and graphical interfaces.
It offers advanced capabilities which include syntax highlighting,
macros, and support for numerous programming languages, making it
suitable for a wide range of development tasks.
Vim: A Versatile Text Editor for Developers
A code editor or IDE should be chosen based on your app’s development needs. For example, if you’re working with JavaScript or TypeScript, VS Code is an excellent choice because it supports these languages well.
2. Version Control Tools
Version control is crucial for tracking changes to your code,
collaborating with other developers, and managing different versions of
your app.
Git
Git
is the most popular version control system used by developers
worldwide, which helps you track changes in your code and share it with
others.
Git allows you to go back to earlier versions of your app and resolve conflicts when multiple developers work on the same code.
Git: The Powerful Version Control System
GitHub
GitHub is a platform that hosts Git
repositories and offers features for collaboration, code reviews, and
issue tracking. It’s ideal for open-source projects and team-based
development.
Git Repository Hosting Platform
GitLab
GitLab is similar to GitHub but offers a Git repository platform with additional DevOps tools like CI/CD (Continuous Integration and Continuous Deployment) pipelines.
GitLab: A Comprehensive DevOps Platform
Bitbucket
Bitbucket is a Git repository management tool with a focus on team collaboration, which is especially popular for private repositories.
GitLab: Private Repository Management
Version control helps you keep track of your code changes and
collaborate with other developers without overwriting each other’s work.
Learning Git is essential for any developer.
3. Package Managers
Managing dependencies is one of the key challenges in app development
and package managers help you automate the process of installing,
updating, and managing third-party libraries or frameworks your app
depends on.
npm (Node Package Manager)
npm is the default package manager for Node.js that will help you manage dependencies and install packages easily when you are working with JavaScript or building web apps.
npm: The Official Package Manager for Node.js
Yarn
Yarn is a faster alternative to npm that also helps manage dependencies for JavaScript projects. Yarn has built-in caching for faster installs and uses a lock file to ensure consistent package versions across different machines.
Yarn: A Faster Package Manager
Homebrew
Homebrew is a package manager for macOS (and Linux) that allows you to install command-line tools and software easily.
Homebrew: Easy Package Management
pip
pip is the default package manager for Python that helps you install and manage Python libraries and dependencies.
pip – Python Package Installer
Using package managers can save you a lot of time by managing all the
dependencies your app needs and making sure they are up to date.
4. Containerization and Virtualization
Containers allow developers to package an app and its dependencies
together, making it easier to run the app in different environments,
such as development, testing, and production. Virtualization tools are
also helpful for testing your app in different environments.
Docker
Docker
is a tool that enables developers to package applications and their
dependencies into containers, and these containers can run consistently
on any machine, whether on your local computer, a cloud server, or in a
production environment.
Docker: The Ultimate Tool for Containerization
Kubernetes
Kubernetes
is a system for automating the deployment, scaling, and management of
containerized applications, which is ideal for larger projects where you
need to manage multiple containers.
Kubernetes: Automate Container Management
Vagrant
Vagrant
is a tool for building and maintaining virtual machine environments, it
allows you to create a virtual machine with the required software and
dependencies for your app, making it easier to share development
environments across teams.
Vagrant: Simplify Virtual Machine Management
Using Docker and Kubernetes ensures your app will run smoothly in different environments, reducing “works on my machine” issues.
5. Database Management Tools
Most modern apps need to interact with a database to store and retrieve data. Whether you’re using a relational database like MySQL or a NoSQL database like MongoDB, managing and interacting with these databases is an essential part of app development.
MySQL Workbench
MySQL Workbench is a graphical tool for managing MySQL databases, it offers an easy-to-use interface for writing queries, creating tables, and managing your database.
MySQL Workbench: Database Management Tool
pgAdmin
pgAdmin
is a management tool for PostgreSQL databases, offering a rich set of
features for interacting with your database, writing queries, and
performing administrative tasks.
pgAdmin: PostgreSQL Management Tool
MongoDB Compass
MongoDB Compass is a GUI for MongoDB that allows you to visualize your data, run queries, and interact with your NoSQL database.
MongoDB Compass: A GUI for MongoDB
DBeaver
DBeaver is a universal database management tool that supports multiple databases, including MySQL, PostgreSQL, SQLite, and others.
DBeaver: Database Management Tool
Having a good database management tool helps you efficiently interact with and manage your app’s database.
6. API Development Tools
Modern apps often rely on APIs (Application Programming Interfaces)
to interact with other services or allow third-party apps to interact
with your app. API development tools help you design, test, and manage
APIs efficiently.
Postman
Postman
is a popular tool for testing APIs, which allows you to send HTTP
requests, view responses, and automate API tests. Postman is especially
helpful during the development and testing phase of your app.
Postman: The Ultimate API Testing Tool
Swagger/OpenAPI
Swagger/OpenAPI
is a framework for designing, building, and documenting RESTful APIs.
Swagger can generate interactive API documentation that makes it easier
for other developers to understand and use your API.
Swagger/OpenAPI: Design and Document APIs
Insomnia
Insomnia is another API testing tool similar to Postman,
but with a focus on simplicity and ease of use. It’s great for
developers who want a lightweight tool to test APIs without too many
distractions.
Insomnia: Simple API Testing
Using API development tools can make it easier to test and debug your app’s integration with external services.
7. Testing Tools
Testing is a crucial step in building modern apps, which ensures that
your app works correctly and provides a good user experience. Whether
you’re testing individual pieces of code (unit testing) or the entire
app (end-to-end testing), the right tools are essential.
JUnit
JUnit is a framework for writing and running unit tests in Java. It’s widely used in the Java development community.
JUnit: Java Unit Testing Framework
Mocha
Mocha is a JavaScript testing framework that runs in Node.js and in the browser, and helps you write tests for your app’s behavior.
Mocha: JavaScript Testing Framework
Selenium
Selenium is a tool for automating web browsers, allowing you to perform end-to-end testing of your web app’s UI.
Selenium: Automate Web Browsers
Jest
Jest is a testing framework for JavaScript that works well with React and other JavaScript frameworks. Jest offers fast and reliable tests with great debugging features.
Jest: A Powerful JavaScript Testing Framework
Good testing tools help you identify bugs early, improve the quality of your app, and ensure that it works as expected.
Continuous Integration and Continuous Deployment (CI/CD) Tools
CI/CD is a modern practice that involves automating
the process of testing, building, and deploying your app. CI/CD tools
help you ensure that your app is always in a deployable state and can be
released to production quickly and reliably.
Jenkins
Jenkins
is a popular open-source automation server that allows you to automate
building, testing, and deploying your app, it integrates with many
version control systems and other tools.
Jenkins: The Ultimate CI/CD Automation Tool
Travis CI
Travis CI is a cloud-based CI/CD service that integrates easily with GitHub and automates the process of testing and deploying your app.
Travis CI: Automate Your Builds and Deployments
CircleCI
CircleCI is a fast, cloud-based CI/CD tool that integrates with GitHub, Bitbucket, and GitLab, and helps automate the testing and deployment of your app.
CircleCI: Automate Your Builds and Deployments
GitLab CI/CD
GitLab CI/CD
offers built-in CI/CD features, allowing you to manage the entire
software development lifecycle from code to deployment in one platform.
Simplify Your DevOps with GitLab CI/CD
CI/CD tools help automate the repetitive tasks of
building, testing, and deploying, saving developers a lot of time and
reducing the chances of human error.
9. Cloud Platforms and Hosting Services
For modern apps, hosting them in the cloud is often the best option,
as cloud platforms provide scalable infrastructure, security, and high
availability for your app.
Amazon Web Services (AWS)
Amazon Web Services (AWS)
is a comprehensive cloud platform offering a wide range of services,
including computing, storage, databases, machine learning, and more. AWS
is ideal for large-scale apps with high traffic.
AWS: Cloud Computing Platform
Microsoft Azure
Microsoft Azure
is a cloud platform offering various services, including hosting,
storage, AI, and databases, which is a popular choice for enterprises
and developers building apps on Microsoft technologies.
Microsoft Azure: Cloud Computing Platform
Google Cloud Platform (GCP)
Google Cloud Platform (GCP)
offers tools for building, deploying, and scaling applications. GCP is
especially popular for apps that rely on machine learning and big data.
Google Cloud Platform (GCP)
Heroku
Heroku
is a platform-as-a-service (PaaS) for building, running, and scaling
apps, which is great for smaller apps or when you need a quick and easy
way to deploy your app.
Heroku: Platform as a Service
Cloud platforms provide the infrastructure your app needs to run in a scalable, secure, and cost-effective manner.
Conclusion
Building modern apps requires a combination of the right tools to
handle different aspects of the development process. Whether you’re
writing code, managing dependencies, testing your app, or deploying it
to the cloud, having the right tools can make a huge difference in your
productivity and the quality of your app.
By using the tools mentioned above, you’ll be well-equipped to build, test, and deploy modern apps efficiently. Happy coding!