http://xmodulo.com/turn-centos-box-into-ospf-router-quagga.html
Quagga is an open source routing software suite that can be used to turn your Linux box into a fully-fledged router that supports major routing protocols like RIP, OSPF, BGP or ISIS router. It has full provisions for IPv4 and IPv6, and supports route/prefix filtering. Quagga can be a life saver in case your production router is down, and you don't have a spare one at your disposal, so are waiting for a replacement. With proper configurations, Quagga can even be provisioned as a production router.
In this tutorial, we will connect two hypothetical branch office networks (e.g., 192.168.1.0/24 and 172.17.1.0/24) that have a dedicated link between them.
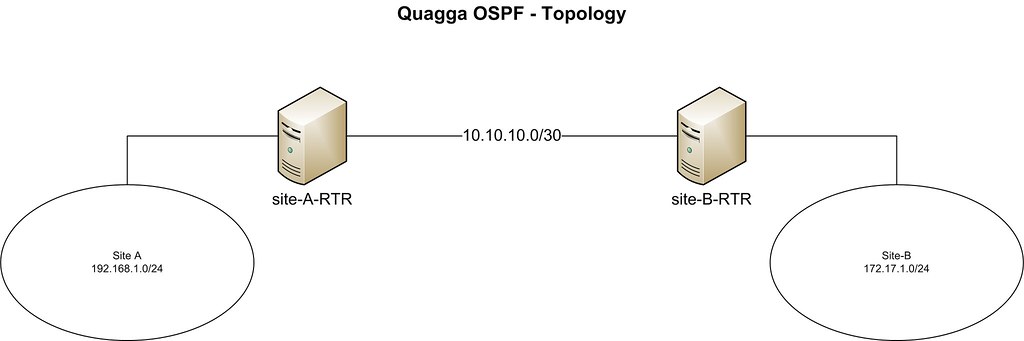
Our CentOS boxes are located at both ends of the dedicated link. The hostnames of the two boxes are set as 'site-A-RTR' and 'site-B-RTR' respectively. IP address details are provided below.
First, we configure the log file for Zebra. For that, enter the global configuration mode in vtysh by typing:
If all goes well, you should be able to ping site-B's peering IP 10.10.10.2 from site-A server.
Note that once Zebra daemon has started, any change made with vtysh's command line interface takes effect immediately. There is no need to restart Zebra daemon after configuration change.
In the next section, we are going to verify our Quagga setup.
In this tutorial, we focused on configuring basic OSPF using Quagga. In general, Quagga allows us to easily configure a regular Linux box to speak dynamic routing protocols such as OSPF, RIP or BGP. Quagga-enabled boxes will be able to communicate and exchange routes with any other router that you may have in your network. Since it supports major open standard routing protocols, it may be a preferred choice in many scenarios. Better yet, Quagga's command line interface is almost identical to that of major router vendors like Cisco or Juniper, which makes deploying and maintaining Quagga boxes very easy.
Hope this helps.
Quagga is an open source routing software suite that can be used to turn your Linux box into a fully-fledged router that supports major routing protocols like RIP, OSPF, BGP or ISIS router. It has full provisions for IPv4 and IPv6, and supports route/prefix filtering. Quagga can be a life saver in case your production router is down, and you don't have a spare one at your disposal, so are waiting for a replacement. With proper configurations, Quagga can even be provisioned as a production router.
In this tutorial, we will connect two hypothetical branch office networks (e.g., 192.168.1.0/24 and 172.17.1.0/24) that have a dedicated link between them.
Our CentOS boxes are located at both ends of the dedicated link. The hostnames of the two boxes are set as 'site-A-RTR' and 'site-B-RTR' respectively. IP address details are provided below.
- Site-A: 192.168.1.0/24
- Site-B: 172.16.1.0/24
- Peering between 2 Linux boxes: 10.10.10.0/30
- Zebra: a core daemon, responsible for kernel interfaces and static routes.
- Ospfd: an IPv4 OSPF daemon.
Install Quagga on CentOS
We start the process by installing Quagga using yum.
# yum install quagga
On CentOS 7, SELinux prevents /usr/sbin/zebra from writing to its
configuration directory by default. This SELinux policy interferes with
the setup procedure we are going to describe, so we want to disable
this policy. For that, either turn off SELinux (which is not recommended), or enable the 'zebra_write_config' boolean as follows. Skip this step if you are using CentOS 6.
# setsebool -P zebra_write_config 1
Without this change, we will see the following error when attempting
to save Zebra configuration from inside Quagga's command shell.Can't open configuration file /etc/quagga/zebra.conf.OS1Uu5.After Quagga is installed, we configure necessary peering IP addresses, and update OSPF settings. Quagga comes with a command line shell called vtysh. The Quagga commands used inside vtysh are similar to those of major router vendors such as Cisco or Juniper.
Phase 1: Configuring Zebra
We start by creating a Zebra configuration file, and launching Zebra daemon.
# cp /usr/share/doc/quagga-XXXXX/zebra.conf.sample /etc/quagga/zebra.conf
# service zebra start
# chkconfig zebra on
Launch vtysh command shell:# service zebra start
# chkconfig zebra on
# vtysh
The prompt will be changed to:
site-A-RTR#
which indicates that you are inside vtysh shell.First, we configure the log file for Zebra. For that, enter the global configuration mode in vtysh by typing:
site-A-RTR# configure terminal
and specify log file location, then exit the mode:
site-A-RTR(config)# log file /var/log/quagga/quagga.log
site-A-RTR(config)# exit
Save configuration permanently:site-A-RTR(config)# exit
site-A-RTR# write
Next, we identify available interfaces and configure their IP addresses as necessary.
site-A-RTR# show interface
Interface eth0 is up, line protocol detection is disabled . . . . . Interface eth1 is up, line protocol detection is disabled . . . . .Configure eth0 parameters:
site-A-RTR# configure terminal
site-A-RTR(config)# interface eth0
site-A-RTR(config-if)# ip address 10.10.10.1/30
site-A-RTR(config-if)# description to-site-B
site-A-RTR(config-if)# no shutdown
Go ahead and configure eth1 parameters:site-A-RTR(config)# interface eth0
site-A-RTR(config-if)# ip address 10.10.10.1/30
site-A-RTR(config-if)# description to-site-B
site-A-RTR(config-if)# no shutdown
site-A-RTR(config)# interface eth1
site-A-RTR(config-if)# ip address 192.168.1.1/24
site-A-RTR(config-if)# description to-site-A-LAN
site-A-RTR(config-if)# no shutdown
Now verify configuration:site-A-RTR(config-if)# ip address 192.168.1.1/24
site-A-RTR(config-if)# description to-site-A-LAN
site-A-RTR(config-if)# no shutdown
site-A-RTR(config-if)# do show interface
Interface eth0 is up, line protocol detection is disabled . . . . . inet 10.10.10.1/30 broadcast 10.10.10.3 . . . . . Interface eth1 is up, line protocol detection is disabled . . . . . inet 192.168.1.1/24 broadcast 192.168.1.255 . . . . .
site-A-RTR(config-if)# do show interface description
Interface Status Protocol Description eth0 up unknown to-site-B eth1 up unknown to-site-A-LANSave configuration permanently, and quit interface configuration mode.
site-A-RTR(config-if)# do write
site-A-RTR(config-if)# exit
site-A-RTR(config)# exit
site-A-RTR#
Quit vtysh shell to come back to Linux shell.site-A-RTR(config-if)# exit
site-A-RTR(config)# exit
site-A-RTR#
site-A-RTR# exit
Next, enable IP forwarding so that traffic can be forwarded between eth0 and eth1 interfaces.
# echo "net.ipv4.ip_forward = 1" >> /etc/sysctl.conf
# sysctl -p /etc/sysctl.conf
Repeat the IP address configuration and IP forwarding enabling steps on site-B server as well.# sysctl -p /etc/sysctl.conf
If all goes well, you should be able to ping site-B's peering IP 10.10.10.2 from site-A server.
Note that once Zebra daemon has started, any change made with vtysh's command line interface takes effect immediately. There is no need to restart Zebra daemon after configuration change.
Phase 2: Configuring OSPF
We start by creating an OSPF configuration file, and starting the OSPF daemon:
# cp /usr/share/doc/quagga-XXXXX/ospfd.conf.sample /etc/quagga/ospfd.conf
# service ospfd start
# chkconfig ospfd on
Now launch vtysh shell to continue with OSPF configuration:# service ospfd start
# chkconfig ospfd on
# vtysh
Enter router configuration mode:
site-A-RTR# configure terminal
site-A-RTR(config)# router ospf
Optionally, set the router-id manually:site-A-RTR(config)# router ospf
site-A-RTR(config-router)# router-id 10.10.10.1
Add the networks that will participate in OSPF:
site-A-RTR(config-router)# network 10.10.10.0/30 area 0
site-A-RTR(config-router)# network 192.168.1.0/24 area 0
Save configuration permanently:site-A-RTR(config-router)# network 192.168.1.0/24 area 0
site-A-RTR(config-router)# do write
Repeat the similar OSPF configuration on site-B as well:
site-B-RTR(config-router)# network 10.10.10.0/30 area 0
site-B-RTR(config-router)# network 172.16.1.0/24 area 0
site-B-RTR(config-router)# do write
The OSPF neighbors should come up now. As long as ospfd is running, any OSPF related configuration change made via vtysh shell takes effect immediately without having to restart ospfd.site-B-RTR(config-router)# network 172.16.1.0/24 area 0
site-B-RTR(config-router)# do write
In the next section, we are going to verify our Quagga setup.
Verification
1. Test with ping
To begin with, you should be able to ping the LAN subnet of site-B from site-A. Make sure that your firewall does not block ping traffic.
[root@site-A-RTR ~]# ping 172.16.1.1 -c 2
2. Check routing tables
Necessary routes should be present in both kernel and Quagga routing tables.
[root@site-A-RTR ~]# ip route
10.10.10.0/30 dev eth0 proto kernel scope link src 10.10.10.1 172.16.1.0/30 via 10.10.10.2 dev eth0 proto zebra metric 20 192.168.1.0/24 dev eth1 proto kernel scope link src 192.168.1.1
[root@site-A-RTR ~]# vtysh
site-A-RTR# show ip route
site-A-RTR# show ip route
Codes: K - kernel route, C - connected, S - static, R - RIP, O - OSPF,
I - ISIS, B - BGP, > - selected route, * - FIB route
O 10.10.10.0/30 [110/10] is directly connected, eth0, 00:14:29
C>* 10.10.10.0/30 is directly connected, eth0
C>* 127.0.0.0/8 is directly connected, lo
O>* 172.16.1.0/30 [110/20] via 10.10.10.2, eth0, 00:14:14
C>* 192.168.1.0/24 is directly connected, eth1
3. Verifying OSPF neighbors and routes
Inside vtysh shell, you can check if necessary neighbors are up, and proper routes are being learnt.
[root@site-A-RTR ~]# vtysh
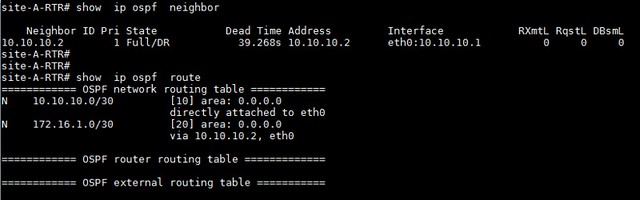
site-A-RTR# show ip ospf neighbor
site-A-RTR# show ip ospf neighbor
In this tutorial, we focused on configuring basic OSPF using Quagga. In general, Quagga allows us to easily configure a regular Linux box to speak dynamic routing protocols such as OSPF, RIP or BGP. Quagga-enabled boxes will be able to communicate and exchange routes with any other router that you may have in your network. Since it supports major open standard routing protocols, it may be a preferred choice in many scenarios. Better yet, Quagga's command line interface is almost identical to that of major router vendors like Cisco or Juniper, which makes deploying and maintaining Quagga boxes very easy.
Hope this helps.