http://www.blackmoreops.com/2015/02/14/linux-file-system-hierarchy
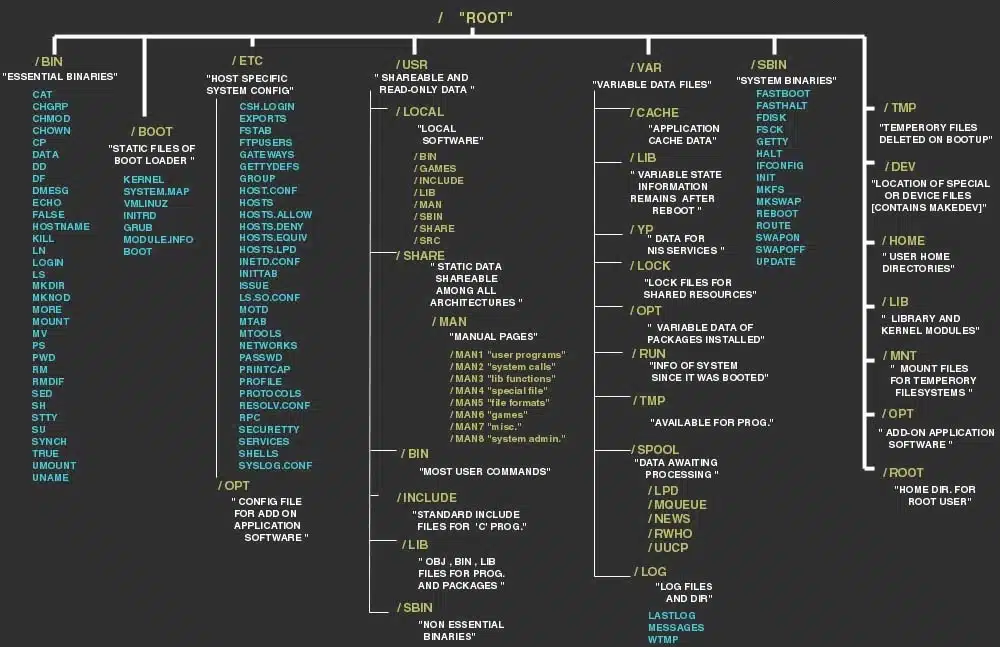
What is a file in Linux? What is file system in Linux? Where are all the configuration files? Where do I keep my downloaded applications? Is there really a filesystem standard structure in Linux? Well, the above image explains Linux file system hierarchy in a very simple and non-complex way. It’s very useful when you’re looking for a configuration file or a binary file. I’ve added some explanation and examples below, but that’s TLDR.

In order to manage all those files in an orderly fashion, man likes to think of them in an ordered tree-like structure on the hard disk, as we know from
While it is reasonably safe to suppose that everything you encounter on a Linux system is a file, there are some exceptions.
Every partition has its own file system. By imagining all those file systems together, we can form an idea of the tree-structure of the entire system, but it is not as simple as that. In a file system, a file is represented by an
Every partition has its own set of inodes; throughout a system with multiple partitions, files with the same inode number can exist.
Each inode describes a data structure on the hard disk, storing the properties of a file, including the physical location of the file data. When a hard disk is initialized to accept data storage, usually during the initial system installation process or when adding extra disks to an existing system, a fixed number of inodes per partition is created. This number will be the maximum amount of files, of all types (including directories, special files, links etc.) that can exist at the same time on the partition. We typically count on having 1 inode per 2 to 8 kilobytes of storage.
At the time a new file is created, it gets a free inode. In that inode is the following information:
What is a file in Linux? What is file system in Linux? Where are all the configuration files? Where do I keep my downloaded applications? Is there really a filesystem standard structure in Linux? Well, the above image explains Linux file system hierarchy in a very simple and non-complex way. It’s very useful when you’re looking for a configuration file or a binary file. I’ve added some explanation and examples below, but that’s TLDR.
What is a file in Linux?
A simple description of the UNIX system, also applicable to Linux, is this:On a UNIX system, everything is a file; if something is not a file, it is a process.This statement is true because there are special files that are more than just files (named pipes and sockets, for instance), but to keep things simple, saying that everything is a file is an acceptable generalization. A Linux system, just like UNIX, makes no difference between a file and a directory, since a directory is just a file containing names of other files. Programs, services, texts, images, and so forth, are all files. Input and output devices, and generally all devices, are considered to be files, according to the system.
In order to manage all those files in an orderly fashion, man likes to think of them in an ordered tree-like structure on the hard disk, as we know from
MS-DOS (Disk Operating System) for instance. The
large branches contain more branches, and the branches at the end
contain the tree’s leaves or normal files. For now we will use this
image of the tree, but we will find out later why this is not a fully
accurate image.| Directory | Description |
|---|---|
| Primary hierarchy root and root directory of the entire file system hierarchy. |
| Essential command binaries that need to be available in single user mode; for all users, e.g., cat, ls, cp. |
| Boot loader files, e.g., kernels, initrd. |
| Essential devices, e.g., /dev/null. |
| Host-specific system-wide configuration filesThere has been controversy over the meaning of the name itself. In early versions of the UNIX Implementation Document from Bell labs, /etc is referred to as the etcetera directory, as this directory historically held everything that did not belong elsewhere (however, the FHS restricts /etc to static configuration files and may not contain binaries). Since the publication of early documentation, the directory name has been re-designated in various ways. Recent interpretations include backronyms such as “Editable Text Configuration” or “Extended Tool Chest”. |
| Configuration files for add-on packages that are stored in /opt/. |
| Configuration files, such as catalogs, for software that processes SGML. |
| Configuration files for the X Window System, version 11. |
| Configuration files, such as catalogs, for software that processes XML. |
| Users’ home directories, containing saved files, personal settings, etc. |
| Libraries essential for the binaries in /bin/ and /sbin/. |
| Alternate format essential libraries. Such directories are optional, but if they exist, they have some requirements. |
| Mount points for removable media such as CD-ROMs (appeared in FHS-2.3). |
| Temporarily mounted filesystems. |
| Optional application software packages. |
| Virtual filesystem providing process and kernel information as files. In Linux, corresponds to a procfs mount. |
| Home directory for the root user. |
| Essential system binaries, e.g., init, ip, mount. |
| Site-specific data which are served by the system. |
| Temporary files (see also /var/tmp). Often not preserved between system reboots. |
| Secondary hierarchy for read-only user data; contains the majority of (multi-)user utilities and applications. |
| Non-essential command binaries (not needed in single user mode); for all users. |
| Standard include files. |
| Libraries for the binaries in /usr/bin/ and /usr/sbin/. |
| Alternate format libraries (optional). |
| Tertiary hierarchy for local data, specific to this host. Typically has further subdirectories, e.g., bin/, lib/, share/. |
| Non-essential system binaries, e.g., daemons for various network-services. |
| Architecture-independent (shared) data. |
| Source code, e.g., the kernel source code with its header files. |
| X Window System, Version 11, Release 6. |
| Variable files—files whose content is expected to continually change during normal operation of the system—such as logs, spool files, and temporary e-mail files. |
| Application cache data. Such data are locally generated as a result of time-consuming I/O or calculation. The application must be able to regenerate or restore the data. The cached files can be deleted without loss of data. |
| State information. Persistent data modified by programs as they run, e.g., databases, packaging system metadata, etc. |
| Lock files. Files keeping track of resources currently in use. |
| Log files. Various logs. |
| Users’ mailboxes. |
| Variable data from add-on packages that are stored in /opt/. |
| Information about the running system since last boot, e.g., currently logged-in users and running daemons. |
| Spool for tasks waiting to be processed, e.g., print queues and outgoing mail queue. |
| Deprecated location for users’ mailboxes. |
| Temporary files to be preserved between reboots. |
Types of files in Linux
Most files are just files, calledregular
files; they contain normal data, for example text files, executable
files or programs, input for or output from a program and so on.While it is reasonably safe to suppose that everything you encounter on a Linux system is a file, there are some exceptions.
Directories: files that are lists of other files.Special files: the mechanism used for input and output. Most special files are in/dev, we will discuss them later.Links: a system to make a file or directory visible in multiple parts of the system’s file tree. We will talk about links in detail.(Domain) sockets: a special file type, similar to TCP/IP sockets, providing inter-process networking protected by the file system’s access control.Named pipes: act more or less like sockets and form a way for processes to communicate with each other, without using network socket semantics.
File system in reality
For most users and for most common system administration tasks, it is enough to accept that files and directories are ordered in a tree-like structure. The computer, however, doesn’t understand a thing about trees or tree-structures.Every partition has its own file system. By imagining all those file systems together, we can form an idea of the tree-structure of the entire system, but it is not as simple as that. In a file system, a file is represented by an
inode, a kind
of serial number containing information about the actual data that makes
up the file: to whom this file belongs, and where is it located on the
hard disk.Every partition has its own set of inodes; throughout a system with multiple partitions, files with the same inode number can exist.
Each inode describes a data structure on the hard disk, storing the properties of a file, including the physical location of the file data. When a hard disk is initialized to accept data storage, usually during the initial system installation process or when adding extra disks to an existing system, a fixed number of inodes per partition is created. This number will be the maximum amount of files, of all types (including directories, special files, links etc.) that can exist at the same time on the partition. We typically count on having 1 inode per 2 to 8 kilobytes of storage.
At the time a new file is created, it gets a free inode. In that inode is the following information:
- Owner and group owner of the file.
- File type (regular, directory, …)
- Permissions on the file
- Date and time of creation, last read and change.
- Date and time this information has been changed in the inode.
- Number of links to this file (see later in this chapter).
- File size
- An address defining the actual location of the file data.
-i option to ls. The inodes have their own separate space on the disk.
No comments:
Post a Comment