https://linuxconfig.org/introduction-to-python-web-scraping-and-the-beautiful-soup-library
If the use of the distribution package manager is preferred and we are using Fedora:
 We
can also observe that each row of the table holds information about a
movie: the title's scores are contained as text inside a
We
can also observe that each row of the table holds information about a
movie: the title's scores are contained as text inside a
We introduced few new elements, let's see them. The first thing we have done, is to retrieve the
The first element provided to the
In this example we just displayed the retrieved data with a very simple formatting, but in a real-world scenario, we might have wanted to perform further manipulations, or store it in a database.
Objective
Learning how to extract information out of an html page using python and the Beautiful Soup library.Requirements
- Understanding of the basics of python and object oriented programming
Difficulty
EASYConventions
- # - requires given linux command to be executed with root privileges either directly as a root user or by use of
sudocommand - $ - given linux command to be executed as a regular non-privileged user
Introduction
Web scraping is a technique which consist in the extraction of data from a web site through the use of dedicated software. In this tutorial we will see how to perform a basic web scraping using python and the Beautiful Soup library. We will usepython3 targeting the homepage of
Rotten Tomatoes, the famous aggregator of reviews and news for films
and tv shows, as a source of information for our exercise. Installation of the Beautiful Soup library
To perform our scraping we will make use of the Beautiful Soup python library, therefore the first thing we need to do is to install it. The library is available in the repositories of all the major GNU\Linux distributions, therefore we can install it using our favorite package manager, or by usingpip, the python native way for installing packages. If the use of the distribution package manager is preferred and we are using Fedora:
$ sudo dnf install python3-beautifulsoup4On Debian and its derivatives the package is called beautifulsoup4:
$ sudo apt-get install beautifulsoup4On Archilinux we can install it via pacman:
$ sudo pacman -S python-beatufilusoup4If we want to use
pip, instead, we can just run: $ pip3 install --user BeautifulSoup4By running the command above with the
--user
flag, we will install the latest version of the Beautiful Soup library
only for our user, therefore no root permissions needed. Of course you
can decide to use pip to install the package globally, but personally I
tend to prefer per-user installations when not using the distribution
package manager. The BeautifulSoup object
Let's begin: the first thing we want to do is to create a BeautifulSoup object. The BeautifulSoup constructor accepts either astring
or a file handle as its first argument. The latter is what interests
us: we have the url of the page we want to scrape, therefore we will use
the urlopen method of the urllib.request library (installed by default): this method returns a file-like object:from bs4 import BeautifulSoup
from urllib.request import urlopen
with urlopen('http://www.rottentomatoes.com') as homepage:
soup = BeautifulSoup(homepage)
soup
object represents the document in its entirety. We can begin navigating
it and extracting the data we want using the built-in methods and
properties. For example, say we want to extract all the links contained
in the page: we know that links are represented by the a tag in html and the actual link is contained in the href attribute of the tag, so we can use the find_all method of the object we just built to accomplish our task:for link in soup.find_all('a'):
print(link.get('href'))
find_all method and specifying a
as the first argument, which is the name of the tag, we searched for
all links in the page. For each link we then retrieved and printed the
value of the href attribute. In BeautifulSoup the
attributes of an element are stored into a dictionary, therefore
retrieving them is very easy. In this case we used the get method, but we could have accessed the value of the href attribute even with the following syntax: link['href']. The complete attributes dictionary itself is contained in the attrs property of the element. The code above will produce the following result: [...]
https://editorial.rottentomatoes.com/
https://editorial.rottentomatoes.com/24-frames/
https://editorial.rottentomatoes.com/binge-guide/
https://editorial.rottentomatoes.com/box-office-guru/
https://editorial.rottentomatoes.com/critics-consensus/
https://editorial.rottentomatoes.com/five-favorite-films/
https://editorial.rottentomatoes.com/now-streaming/
https://editorial.rottentomatoes.com/parental-guidance/
https://editorial.rottentomatoes.com/red-carpet-roundup/
https://editorial.rottentomatoes.com/rt-on-dvd/
https://editorial.rottentomatoes.com/the-simpsons-decade/
https://editorial.rottentomatoes.com/sub-cult/
https://editorial.rottentomatoes.com/tech-talk/
https://editorial.rottentomatoes.com/total-recall/
[...]
find_all method returns all Tag
objects that matches the specified filter. In our case we just
specified the name of the tag which should be matched, and no other
criteria, so all links are returned: we will see in a moment how to
further restrict our search. A test case: retrieving all "Top box office" titles
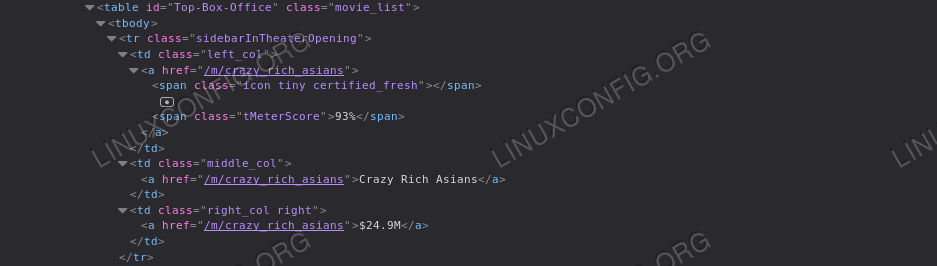
Let's perform a more restricted scraping. Say we want to retrieve all the titles of the movies which appear in the "Top Box Office" section of Rotten Tomatoes homepage. The first thing we want to do is to analyze the page html for that section: doing so, we can observe that the element we need are all contained inside atable element with the "Top-Box-Office" id:
Top Box Office
span
element with class "tMeterScore" inside the first cell of the row,
while the string representing the title of the movie is contained in the
second cell, as the text of the a tag. Finally, the last
cell contains a link with the text that represents the box office
results of the film. With those references, we can easily retrieve all
the data we want: from bs4 import BeautifulSoup
from urllib.request import urlopen
with urlopen('https://www.rottentomatoes.com') as homepage:
soup = BeautifulSoup(homepage.read(), 'html.parser')
# first we use the find method to retrieve the table with 'Top-Box-Office' id
top_box_office_table = soup.find('table', {'id': 'Top-Box-Office'})
# than we iterate over each row and extract movies information
for row in top_box_office_table.find_all('tr'):
cells = row.find_all('td')
title = cells[1].find('a').get_text()
money = cells[2].find('a').get_text()
score = row.find('span', {'class': 'MeterScore'}).get_text()
print('{0} -- {1} (TomatoMeter: {2})'.format(title, money, score))
Crazy Rich Asians -- .9M (TomatoMeter: 93%) The Meg -- .9M (TomatoMeter: 46%) The Happytime Murders -- .6M (TomatoMeter: 22%) Mission: Impossible - Fallout -- .2M (TomatoMeter: 97%) Mile 22 -- .5M (TomatoMeter: 20%) Christopher Robin -- .4M (TomatoMeter: 70%) Alpha -- .1M (TomatoMeter: 83%) BlacKkKlansman -- .2M (TomatoMeter: 95%) Slender Man -- .9M (TomatoMeter: 7%) A.X.L. -- .8M (TomatoMeter: 29%)
table with 'Top-Box-Office' id, using the find method. This method works similarly to find_all,
but while the latter returns a list which contains the matches found,
or is empty if there are no correspondence, the former returns always
the first result or None if an element with the specified criteria is not found. The first element provided to the
find method is the name of the tag to be considered in the search, in this case table.
As a second argument we passed a dictionary in which each key
represents an attribute of the tag with its corresponding value. The
key-value pairs provided in the dictionary represents the criteria that
must be satisfied for our search to produce a match. In this case we
searched for the id attribute with "Top-Box-Office" value. Notice that since each id must be unique in an html page, we could just have omitted the tag name and use this alternative syntax: top_box_office_table = soup.find(id='Top-Box-Office')
Tag object, we used the find_all
method to find all the rows, and iterate over them. To retrieve the
other elements, we used the same principles. We also used a new method, get_text:
it returns just the text part contained in a tag, or if none is
specified, in the entire page. For example, knowing that the movie score
percentage are represented by the text contained in the span element with the tMeterScore class, we used the get_text method on the element to retrieve it. In this example we just displayed the retrieved data with a very simple formatting, but in a real-world scenario, we might have wanted to perform further manipulations, or store it in a database.

No comments:
Post a Comment