http://gigaom.com/2013/08/14/facebooks-trillion-edge-hadoop-based-graph-processing-engine
Summary:
Facebook has detailed its extensive improvements to the open
source Apache Giraph graph-processing platform. The project, which is
built on top of Hadoop, can now process trillions of connections between
people, places and things in minutes.
People following the open source Giraph project likely know that
Facebook was experimenting with it, and on Wednesday the company detailed just how heavily it’s leaning on Giraph. Facebook scaled it to handle trillions of connections among users and their behavior, as the core of its Open Graph tool.
Oh, and now anyone can download Giraph, which is an Apache Software Foundation project, with Facebook’s improvements baked in.
Graphs, you might recall from our earlier coverage, are the new hotness in the big data world. Graph-processing engines and graph databases use a system of nodes (e.g., Facebook users, their Likes and their interests) and edges (e.g., the connections between all of them) in order to analyze the relationships among groups of people, places and things.
Giraph is an open source take on Pregel, the graph-processing platform that powers Google PageRank, among other things. The National Security Agency has its own graph-processing platform capable of analyzing an astounding 70 trillion edges, if not more by now. Twitter has a an open-source platform called Cassovary that could handle billions of edges as of March 2012.
Even though it’s not using a specially built graph-processing engines, Pinterest utilizes a graph data architecture as a way of keeping track who and what its users are following.
There are several other popular open source graph projects, as well, including commercially backed ones such as Neo4j and GraphLab.
What makes Giraph particularly interesting is that it’s built to take advantage of Hadoop, the big data platform already in place at countless companies, and nowhere at a larger scale than at Facebook. This, Facebook engineer and Giraph contributor Avery Ching wrote in his blog post explaining how the company’s Giraph engineering effort, was among the big reasons for choosing it over alternative platforms.
 But Hadoop compatibility only takes you so far:
But Hadoop compatibility only takes you so far:
And although Ching doesn’t provide any context, we can take for granted that the performance Facebook has been able to drive out of Giraph really is impressive:
 When you’re talking about processing that much data and that many variables in minutes, it’s usually a good thing.
When you’re talking about processing that much data and that many variables in minutes, it’s usually a good thing.
The best thing about all of this for the rest of the Hadoop-using world: the Apache Giraph project has implemented Facebook’s improvement into the 1.0.0 version of the platform, which it claims is stable and ready for use.
Oh, and now anyone can download Giraph, which is an Apache Software Foundation project, with Facebook’s improvements baked in.
Graphs, you might recall from our earlier coverage, are the new hotness in the big data world. Graph-processing engines and graph databases use a system of nodes (e.g., Facebook users, their Likes and their interests) and edges (e.g., the connections between all of them) in order to analyze the relationships among groups of people, places and things.
Giraph is an open source take on Pregel, the graph-processing platform that powers Google PageRank, among other things. The National Security Agency has its own graph-processing platform capable of analyzing an astounding 70 trillion edges, if not more by now. Twitter has a an open-source platform called Cassovary that could handle billions of edges as of March 2012.
Even though it’s not using a specially built graph-processing engines, Pinterest utilizes a graph data architecture as a way of keeping track who and what its users are following.
There are several other popular open source graph projects, as well, including commercially backed ones such as Neo4j and GraphLab.
What makes Giraph particularly interesting is that it’s built to take advantage of Hadoop, the big data platform already in place at countless companies, and nowhere at a larger scale than at Facebook. This, Facebook engineer and Giraph contributor Avery Ching wrote in his blog post explaining how the company’s Giraph engineering effort, was among the big reasons for choosing it over alternative platforms.

Source: Facebook
“We selected three production applications (label propagation, variants of page rank, and k-means clustering) to drive the direction of our development. Running these applications on graphs as large as the full Facebook friendship graph (over 1 billion users and hundreds of billions of friendships) required us to add features and major scalability improvements to Giraph”Ching explained Facebook’s scalability and performance improvements in some detail.
And although Ching doesn’t provide any context, we can take for granted that the performance Facebook has been able to drive out of Giraph really is impressive:
“On 200 commodity machines we are able to run an iteration of page rank on an actual 1 trillion edge social graph formed by various user interactions in under four minutes with the appropriate garbage collection and performance tuning. We can cluster a Facebook monthly active user data set of 1 billion input vectors with 100 features into 10,000 centroids with k-means in less than 10 minutes per iteration.”

Source: Facebook
The best thing about all of this for the rest of the Hadoop-using world: the Apache Giraph project has implemented Facebook’s improvement into the 1.0.0 version of the platform, which it claims is stable and ready for use.



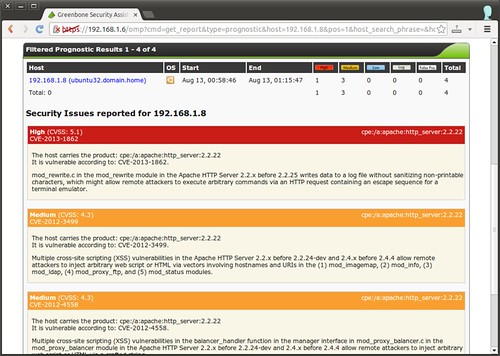

 Figure 1. Android Bootloader Screen
Figure 1. Android Bootloader Screen
 Figure 2. MultiROM "Add ROM" Screen
Figure 2. MultiROM "Add ROM" Screen
 Figure 3. MultiROM Boot Menu
Figure 3. MultiROM Boot Menu
 Figure 4. Ubuntu Touch on the Nexus 7!
Figure 4. Ubuntu Touch on the Nexus 7!
 Pong!
Pong!

