http://www.linuxjournal.com/content/server-hardening
Server hardening. The very words conjure up images of tempering soft
steel into an unbreakable blade, or taking soft clay and firing it in
a kiln, producing a hardened vessel that will last many years. Indeed,
server hardening is very much like that. Putting an unprotected server
out on the Internet is like putting chum in the ocean water you are
swimming in—it won't be long and you'll have a lot of excited sharks
circling you, and the outcome is unlikely to be good. Everyone knows it,
but sometimes under the pressure of deadlines, not to mention the
inevitable push from the business interests to prioritize those things
with more immediate visibility and that add to the bottom line, it can
be difficult to keep up with even what threats you need to mitigate,
much less the best techniques to use to do so. This is how corners get
cut—corners that increase our risk of catastrophe.
This isn't entirely inexcusable. A sysadmin must necessarily be a
jack of all trades, and security is only one responsibility that must
be considered, and not the one most likely to cause immediate pain.
Even in organizations that have dedicated security staff, those
parts of the organization dedicated to it often spend their time
keeping up with the nitty gritty of the latest exploits and can't know
the stack they are protecting as well as those who are knee deep in
maintaining it. The more specialized and diversified the separate
organizations, the more isolated each group becomes from the big
picture. Without the big picture, sensible trade-offs between security
and functionality are harder to make. Since a deep and thorough
knowledge of the technology stack along with the business it serves is
necessary to do a thorough job with security, it sometimes seems
nearly hopeless.
A truly comprehensive work on server hardening would be beyond the
scope not only of a single article, but a single (very large) book,
yet all is not lost. It is true that there can be no "one true
hardening procedure" due to the many and varied environments,
technologies and purposes to which those technologies are put, but it
is also true that you can develop a methodology for governing those
technologies and the processes that put the technology to use that can
guide you toward a sane setup. You can boil down the essentials to a
few principles that you then can apply across the board. In this article,
I explore some examples of application.
I also should say that server hardening, in itself, is almost a
useless endeavor if you are going to undercut yourself with lazy
choices like passwords of "abc123" or lack a holistic approach to
security in the environment. Insecure coding practices can mean that
the one hole you open is gaping, and users e-mailing passwords can
negate all your hard work. The human element is key, and that means
fostering security consciousness at all steps of the process.
Security that is bolted on instead of baked in will never be as
complete or as easy to maintain, but when you don't have executive support
for organizational standards, bolting it on may be the best you can do.
You can sleep well though knowing that at least the Linux server
for which you are responsible is in fact properly if not exhaustively
secured.
The single most important principle of server hardening is this:
minimize your attack surface. The reason is simple and intuitive: a
smaller target is harder to hit. Applying this principle across all
facets of the server is essential. This begins with installing
only the specific packages and software that are exactly necessary for the
business purpose of the server and the minimal set of management and
maintenance packages. Everything present must be vetted and trusted
and maintained. Every line of code that can be run is another
potential exploit on your system, and what is not installed can not
be used against you. Every distribution and service of which I am
aware has an option for a minimal install, and this is always where
you should begin.
The second most important principle is like it: secure that which must
be exposed. This likewise spans the environment from physical access
to the hardware, to encrypting everything that you can everywhere—at
rest on the disk, on the network and everywhere in between. For the
physical location of the server, locks, biometrics, access logs—all
the tools you can bring to bear to controlling and recording who gains
physical access to your server are good things, because physical access, an
accessible BIOS and a bootable USB drive are just one combination
that can mean that your server might as well have grown legs and
walked away with all your data on it. Rogue, hidden wireless SSIDs
broadcast from a USB device can exist for some time before being
stumbled upon.
For the purposes of this article though, I'm going to make a few
assumptions that will shrink the topics to cover a bit. Let's assume
you are putting a new Linux-based server on a cloud service like
AWS or Rackspace. What do you need to do first? Since this is in
someone else's data center, and you already have vetted the physical
security practices of the provider (right?), you begin with your
distribution of choice and a minimal install—just enough to boot and
start SSH so you can access your shiny new server.
Within the parameters of this example scenario, there are levels of concern
that differ depending on the purpose of the server, ranging from
"this is a toy I'm playing with, and I don't care what happens to
it"
all the way to "governments will topple and masses of people die if
this information is leaked", and although a different level of paranoia
and effort needs to be applied in each case, the principles remain the same.
Even if you don't care what ultimately happens to the server, you
still don't want it joining a botnet and contributing to Internet
Mayhem. If you don't care, you are bad and you should feel bad.
If you are setting up a server for the latter purpose, you are
probably more expert than myself and have no reason to be reading
this article, so let's split the difference and assume that should
your server be cracked, embarrassment, brand damage and loss of
revenue (along with your job) will ensue.
In any of these cases, the very first thing to do is tighten your
network access. If the hosting provider provides a mechanism for
this, like Amazon's "Zones", use it, but don't stop there.
Underneath
securing what must be exposed is another principle: layers
within layers containing hurdle after hurdle. Increase the effort
required to reach the final destination, and you reduce the number
that are willing and able to reach it. Zones, or network firewalls,
can fail due to bugs, mistakes and who knows what factors that could come into
play. Maximizing redundancy and backup systems in the case of failure
is a good in itself. All of the most celebrated data thefts have
happened when not just some but all of the advice contained in this
article was ignored, and if only one hurdle had required some effort
to surmount, it is likely that those responsible would have moved on
to someone else with lower hanging fruit. Don't be the lower hanging
fruit. You don't always have to outrun the bear.
The first principle, that which is not present (installed or running)
can not be used against you, requires that you ensure you've both closed
down and turned off all unnecessary services and ports in all
runlevels and made them inaccessible via your server's firewall, in
addition to whatever other firewalling you are doing on the network.
This can be done via your distribution's tools or simply by editing
filenames in /etc/rcX.d directories. If you aren't sure if you need
something, turn it off, reboot, and see what breaks.
But, before doing the above, make sure you have an emergency console back
door first! This won't be the last time you need it. When just
beginning to tinker with securing a server, it is likely you will lock
yourself out more than once. If your provider doesn't provide a
console that works when the network is inaccessible, the next
best thing is to take an image and roll back if the server goes dark.
I suggest first doing two things: running
ps -ef and making sure
you understand what all running processes are doing, and
lsof -ni |
grep LISTEN to make sure you understand why all the listening ports
are open, and that the process you expect has opened them.
For instance, on one of my servers running WordPress, the results are these:
# ps -ef | grep -v \] | wc -l
39
I won't list out all of my process names, but after pulling out all the
kernel processes, I have 39 other processes running, and I know
exactly what all of them are and why they are running. Next I
examine:
# lsof -ni | grep LISTEN
mysqld 1638 mysql 10u IPv4 10579 0t0 TCP
127.0.0.1:mysql (LISTEN)
sshd 1952 root 3u IPv4 11571 0t0 TCP *:ssh (LISTEN)
sshd 1952 root 4u IPv6 11573 0t0 TCP *:ssh (LISTEN)
nginx 2319 root 7u IPv4 12400 0t0 TCP *:http (LISTEN)
nginx 2319 root 8u IPv4 12401 0t0 TCP *:https (LISTEN)
nginx 2319 root 9u IPv6 12402 0t0 TCP *:http (LISTEN)
nginx 2320 www-data 7u IPv4 12400 0t0 TCP *:http (LISTEN)
nginx 2320 www-data 8u IPv4 12401 0t0 TCP *:https (LISTEN)
nginx 2320 www-data 9u IPv6 12402 0t0 TCP *:http (LISTEN)
This is exactly as I expect, and it's the minimal set of ports necessary
for the purpose of the server (to run WordPress).
Now, to make sure only the necessary ports are open, you need to tune
your firewall. Most hosting providers, if you use one of their
templates, will by default have all rules set to "accept". This is
bad. This defies the second principle: whatever must be exposed must
be secured. If, by some accident of nature, some software opened a
port you did not expect, you need to make sure it will be
inaccessible.
Every distribution has its tools for managing a firewall, and
others are available in most package managers. I don't bother with
them, as iptables (once you gain some familiarity with it) is fairly
easy to understand and use, and it is the same on all systems. Like
vi, you can expect its presence everywhere, so it pays to be able
to use it. A basic firewall looks something like this:
# make sure forwarding is off and clear everything
# also turn off ipv6 cause if you don't need it
# turn it off
sysctl net.ipv6.conf.all.disable_ipv6=1
sysctl net.ipv4.ip_forward=0
iptables -F
iptables --flush
iptables -t nat --flush
iptables -t mangle --flush
iptables --delete-chain
iptables -t nat --delete-chain
iptables -t mangle --delete-chain
#make the default -drop everything
iptables --policy INPUT DROP
iptables --policy OUTPUT ACCEPT
iptables --policy FORWARD DROP
#allow all in loopback
iptables -A INPUT -i lo -j ACCEPT
#allow related
iptables -A INPUT -m state --state
↪ESTABLISHED,RELATED -j ACCEPT
#allow ssh
iptables -A INPUT -m tcp -p tcp --dport 22 -j ACCEPT
You can get fancy, wrap this in a script, drop a file in
/etc/rc.d, link it to the runlevels in /etc/rcX.d, and have it start
right after networking, or it might be sufficient for your purposes to
run it straight out of /etc/rc.local. Then you modify this file as
requirements change. For instance, to allow ssh, http and https
traffic, you can switch the last line above to this one:
iptables -A INPUT -p tcp -m state --state NEW -m
↪multiport --dports ssh,http,https -j ACCEPT
More specific rules are better. Let's say what you've built is an
intranet server, and you know where your traffic will be coming from
and on what interface. You instead could add something like this to the bottom of your
iptables script:
iptables -A INPUT -i eth0 -s 192.168.1.0/24 -p tcp
↪-m state --state NEW -m multiport --dports http,https
There are a couple things to consider in this example that you
might need to tweak. For one, this allows all outbound traffic
initiated from the server. Depending on your needs and paranoia level,
you may not wish to do so. Setting outbound traffic to default deny
will significantly complicate maintenance for things like security
updates, so weigh that complication against your level of concern
about rootkits communicating outbound to phone home. Should you go
with default deny for outbound, iptables is an extremely powerful and
flexible tool—you can control outbound communications based on
parameters like process name and owning user ID, rate limit
connections—almost anything you can think of—so if you have the time
to experiment, you can control your network traffic with a very high
degree of granularity.
Second, I'm setting the default to
DROP instead of
REJECT.
DROP
is a bit of security by obscurity. It can discourage a script kiddie
if his port scan takes too long, but since you have commonly scanned
ports open, it will not deter a determined attacker, and it might
complicate your own troubleshooting as you have to wait for the
client-side timeout in the case you've blocked a port in iptables,
either on
purpose or by accident. Also, as I've detailed in a previous article
in
Linux Journal (
http://www.linuxjournal.com/content/back-dead-simple-bash-complex-ddos), TCP-level rejects are very useful in high
traffic situations to clear out the resources used to track
connections statefully on the server and on network gear farther out.
Your mileage may vary.
Finally, your distribution's minimal install might not have sysctl
installed or on by default. You'll need that, so make sure it is on
and works. It makes inspecting and changing system values much easier,
as most versions support tab auto-completion. You also might need to
include full paths to the binaries (usually /sbin/iptables and
/sbin/sysctl), depending on the base path variable of your particular
system.
All of the above probably should be finished within a few minutes of
bringing up the server. I recommend not opening the ports for your
application until after you've installed and configured the
applications you are running on the server. So at the point when you
have a new minimal server with only SSH open, you should apply all
updates using your distribution's method. You can decide now if you
want to do this manually on a schedule or set them to automatic, which
your distribution probably has a mechanism to do. If not, a script
dropped in cron.daily will do the trick. Sometimes updates break
things, so evaluate carefully. Whether you do automatic updates or
not, with the frequency with which critical flaws that sometimes
require manual configuration changes are being uncovered right now,
you need to monitor the appropriate lists and sites for
critical security updates to your stack manually, and apply them as necessary.
Once you've dealt with updates, you can move on and continue to
evaluate your server against the two security principles of 1) minimal
attack surface and 2) secure everything that must be exposed. At
this point, you are pretty solid on point one. On point two, there is more
you can yet do.
The concept of hurdles requires that you not allow root to log in
remotely. Gaining root should be at least a two-part process. This
is easy enough; you simply set this line in /etc/ssh/sshd_config:
PermitRootLogin no
For that matter, root should not be able to
log in directly at all. The account should have no password and should
be accessible only via sudo—another hurdle to clear.
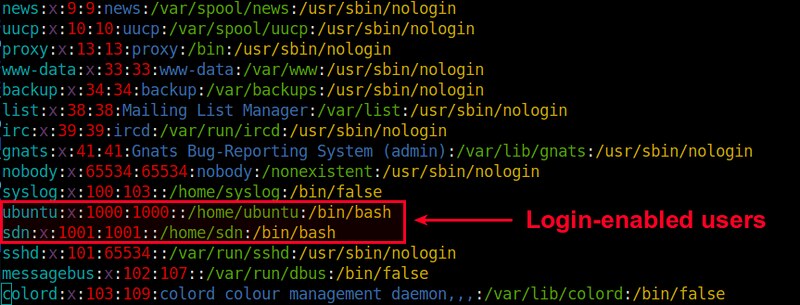
If a user doesn't need to have remote login, don't allow it, or better
said, allow only users that you know need remote access. This satisfies
both principles. Use the
AllowUsers and
AllowGroups settings in
/etc/ssh/sshd_config to make sure you are allowing only the necessary
users.
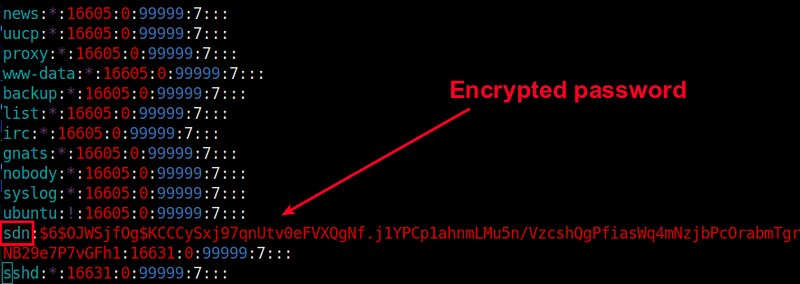
You can set a password policy on your server to require a complex
password for any and all users, but I believe it is generally a better
idea to bypass crackable passwords altogether and use key-only login,
and have the key require a complex passphrase. This raises the bar
for cracking into your system, as it is virtually impossible to brute
force an RSA key. The key could be physically stolen from your client
system, which is why you need the complex passphrase. Without getting
into a discussion of length or strength of key or passphrase, one
way to create it is like this:
ssh-keygen -t rsa
Then when prompted, enter and re-enter the desired passphrase. Copy
the public portion (id_rsa.pub or similar) into a file in the user's
home directory called ~/.ssh/authorized_keys, and then in a new terminal
window, try logging in, and troubleshoot as necessary. I store the key
and the passphrase in a secure data vault provided by Personal,
Inc. (
https://personal.com), and this will allow me, even if away from
home and away from my normal systems, to install the key and
have the passphrase to unlock it, in case an emergency arises.
(Disclaimer: Personal is the startup I work with currently.)
Once it works, change this line in /etc/ssh/sshd_config:
PasswordAuthentication no
Now you can log in only with the key. I still recommend keeping a
complex password for the users, so that when you
sudo, you have that
layer of protection as well. Now to take complete control of your
server, an attacker needs your private key, your passphrase and your
password on the server—hurdle after hurdle. In fact, in my company,
we also use multi-factor authentication in addition to these other
methods, so you must have the key, the passphrase, the pre-secured
device that will receive the notification of the login request and
the user's password. That is a pretty steep hill to climb.
Encryption is a big part of keeping your server secure—encrypt
everything that matters to you. Always be aware of how data,
particularly authentication data, is stored and transmitted. Needless
to say, you never should allow login or connections over an
unencrypted channel like FTP, Telnet, rsh or other legacy protocols.
These are huge no-nos that completely undo all the hard work you've
put into securing your server. Anyone who can gain access to a switch
nearby and perform reverse arp poisoning to mirror your traffic will
own your servers. Always use sftp or scp for file transfers and ssh
for secure shell access. Use https for logins to your applications, and
never store passwords, only hashes.
Even with strong encryption in use, in the recent past, many flaws
have been found in widely used programs and protocols—get used to
turning ciphers on and off in both OpenSSH and OpenSSL. I'm not
covering Web servers here, but the lines of interest you would put in
your /etc/ssh/sshd_config file would look something like this:
Ciphers aes128-ctr,aes192-ctr,aes256-ctr,arcfour256,arcfour128
MACs hmac-sha1,umac-64@openssh.com,hmac-ripemd160
Then you can add or remove as necessary. See
man sshd_config for all the details.
Depending on your level of paranoia and the purpose of your server, you
might be tempted to stop here. I wouldn't. Get used to installing,
using and tuning a few more security essentials, because these last
few steps will make you exponentially more secure. I'm well into
principle two now (secure everything that must be exposed), and I'm bordering
on the third principle: assume that every measure will be defeated.
There is definitely a point of diminishing returns with the third
principle, where the change to the risk does not justify the
additional time and effort, but where that point falls is something
you and your organization have to decide.
The fact of the matter is that even though you've locked down your
authentication, there still exists the chance, however small, that a
configuration mistake or an update is changing/breaking your config, or
by blind luck an attacker could find a way into your system, or
even that the system came with a backdoor. There are a few things you
can do that will further protect you from those risks.
Speaking of backdoors, everything from phones to the
firmware of hard drives has backdoors pre-installed. Lenovo has been
caught no less than three times pre-installing rootkits, and Sony
rooted customer systems in a misguided attempt at DRM. A programming
mistake in OpenSSL left a hole open that the NSA has been exploiting to
defeat encryption for at least a decade without informing the
community, and this was apparently only one of several. In the late
2000s, someone anonymously attempted to insert a two-line programming
error into the Linux kernel that would cause a remote root exploit
under certain conditions. So suffice it to say, I personally do not trust
anything sourced from the NSA, and I turn SELinux off because I'm a
fan of warrants and the fourth amendment. The instructions are
generally available, but usually all you need to do is make this
change to /etc/selinux/config:
#SELINUX=enforcing # comment out
SELINUX=disabled # turn it off, restart the system
In the spirit of turning off and blocking what isn't needed, since
most of the malicious traffic on the Internet comes from just a few
sources, why do you need to give them a shot at cracking your servers?
I run a short script that collects various blacklists of exploited
servers in botnets, Chinese and Russian CIDR ranges and so on, and creates
a blocklist from them, updating once a day. Back in the day, you
couldn't do this, as iptables gets bogged down matching more than a
few thousand lines, so having a rule for every malicious IP out there
just wasn't feasible. With the maturity of the ipset project, now it
is. ipset uses a binary search algorithm that adds only one pass to
the search each time the list doubles, so an arbitrarily large
list can be searched efficiently for a match, although I believe there
is a limit of 65k entries in the ipset table.
To make use of it, add this at the bottom of your iptables script:
#create iptables blocklist rule and ipset hash
ipset create blocklist hash:net
iptables -I INPUT 1 -m set --match-set blocklist
↪src -j DROP
Then put this somewhere executable and run it out of cron once a day:
#!/bin/bash
PATH=$PATH:/sbin
WD=`pwd`
TMP_DIR=$WD/tmp
IP_TMP=$TMP_DIR/ip.temp
IP_BLOCKLIST=$WD/ip-blocklist.conf
IP_BLOCKLIST_TMP=$TMP_DIR/ip-blocklist.temp
list="chinese nigerian russian lacnic exploited-servers"
BLOCKLISTS=(
"http://www.projecthoneypot.org/list_of_ips.php?t=d&rss=1" # Project
↪Honey Pot Directory of Dictionary Attacker IPs
"http://check.torproject.org/cgi-bin/TorBulkExitList.py?ip=1.1.1.1"
↪# TOR Exit Nodes
"http://www.maxmind.com/en/anonymous_proxies" # MaxMind GeoIP
↪Anonymous Proxies
"http://danger.rulez.sk/projects/bruteforceblocker/blist.php"
↪# BruteForceBlocker IP List
"http://rules.emergingthreats.net/blockrules/rbn-ips.txt"
↪# Emerging Threats - Russian Business Networks List
"http://www.spamhaus.org/drop/drop.lasso" # Spamhaus Dont Route
↪Or Peer List (DROP)
"http://cinsscore.com/list/ci-badguys.txt" # C.I. Army Malicious
↪IP List
"http://www.openbl.org/lists/base.txt" # OpenBLOCK.org 30 day List
"http://www.autoshun.org/files/shunlist.csv" # Autoshun Shun List
"http://lists.blocklist.de/lists/all.txt" # blocklist.de attackers
)
cd $TMP_DIR
# This gets the various lists
for i in "${BLOCKLISTS[@]}"
do
curl "$i" > $IP_TMP
grep -Po '(?:\d{1,3}\.){3}\d{1,3}(?:/\d{1,2})?' $IP_TMP >>
$IP_BLOCKLIST_TMP
done
for i in `echo $list`; do
# This section gets wizcrafts lists
wget --quiet http://www.wizcrafts.net/$i-iptables-blocklist.html
# Grep out all but ip blocks
cat $i-iptables-blocklist.html | grep -v \< | grep -v \: |
↪grep -v \; | grep -v \# | grep [0-9] > $i.txt
# Consolidate blocks into master list
cat $i.txt >> $IP_BLOCKLIST_TMP
done
sort $IP_BLOCKLIST_TMP -n | uniq > $IP_BLOCKLIST
rm $IP_BLOCKLIST_TMP
wc -l $IP_BLOCKLIST
ipset flush blocklist
egrep -v "^#|^$" $IP_BLOCKLIST | while IFS= read -r ip
do
ipset add blocklist $ip
done
#cleanup
rm -fR $TMP_DIR/*
exit 0
It's possible you don't want all these blocked. I usually leave tor
exit nodes open to enable anonymity, or if you do business in China,
you certainly can't block every IP range coming from there. Remove
unwanted items from the URLs to be downloaded. When I turned this on,
within 24 hours, the number of banned IPs triggered by brute-force crack
attempts on SSH dropped from hundreds to less than ten.
Although there are many more areas to be hardened, since according to
principle three we assume all measures will be defeated, I will have to
leave things like locking down cron and bash as well as automating
standard security configurations across environments for another day.
There are a few more packages I consider security musts,
including multiple methods to check for intrusion (I run both
chkrootkit and rkhunter to update signatures and scan my systems at
least daily). I want to conclude with one last must-use tool: Fail2ban.
Fail2ban is available in virtually every distribution's repositories
now, and it has become my go-to. Not only is it an extensible Swiss-army
knife of brute-force authentication prevention, it comes with an
additional bevy of filters to detect other attempts to do bad things
to your system. If you do nothing but install it, run it, keep it
updated and turn on its filters for any services you run, especially
SSH, you will be far better off than you were otherwise. As for me, I
have other higher-level software like WordPress log to auth.log for
filtering and banning of malefactors with Fail2ban. You can
custom-configure how long to ban based on how many filter matches (like
failed login attempts of various kinds) and specify longer bans for
"recidivist" abusers that keep coming back.
Here's one example of the extensibility of the tool. During log
review (another important component of a holistic security approach), I
noticed many thousands of the following kinds of probes, coming
especially from China:
sshd[***]: Received disconnect from **.**.**.**: 11: Bye Bye [preauth]
sshd[***]: Received disconnect from **.**.**.**: 11: Bye Bye [preauth]
sshd[***]: Received disconnect from **.**.**.**: 11: Bye Bye [preauth]
There were two forms of this, and I could not find any explanation of
a known exploit that matched this pattern, but there had to be a reason
I was getting so many so quickly. It wasn't enough to be a denial of
service, but it was a steady flow. Either it was a zero-day exploit
or some algorithm sending malformed requests of various kinds hoping
to trigger a memory problem in hopes of uncovering an exploit—in any
case, there was no reason to allow them to continue.
I added this line to the
failregex = section of
/etc/fail2ban/filter.d/sshd.local:
^%(__prefix_line)sReceived disconnect from :
↪11: (Bye Bye)? \[preauth\]$
Within minutes, I had banned 20 new IP addresses, and my logs were
almost completely clear of these lines going forward.
By now, you've seen my three primary principles of server hardening in
action enough to know that systematically applying them to your
systems will have you churning out reasonably hardened systems in no
time. But, just to reiterate one more time:
-
Minimize attack surface.
-
Secure whatever remains and must be exposed.
-
Assume all security measures will be defeated.
Feel free to give me a shout and let me know what you thought about the
article. Let me know your thoughts on what I decided to include, any major omissions I cut for the
sake of space you thought should have been included, and things you'd
like to see in the future!