http://www.linuxjournal.com/content/sharing-admin-privileges-many-hosts-securely
The problem:
you have a large team of admins, with a substantial turnover rate. Maybe
contractors come and go. Maybe you have tiers of access, due to
restrictions based on geography, admin level or even citizenship (as with
some US government contracts). You need to give these people
administrative access to dozens (perhaps hundreds) of hosts, and you can't
manage all their accounts on all the hosts.
This problem arose in the large-scale enterprise in which I work, and our
team worked out a solution that:
-
Does not require updating accounts on more than one host whenever a
team member arrives or leaves.
-
Does not require deletion or replacement of Secure
Shell (SSH) keys.
-
Does not require management of individual SSH keys.
-
Does not require distributed sudoers or other privileged-access
management tools (which may not be supported by some Linux-based
appliances anyway).
-
And most important,
does not require sharing of passwords or key
passphrases.
It works between any UNIX or Linux platforms that understand SSH key trust
relationships. I personally have made use of it on a half-dozen different
Linux distros, as well as Solaris, HP-UX, Mac OS X and some BSD variants.
In our case, the hosts to be managed were several dozen Linux-based
special-purpose appliances that did not support central account management
tools or sudo. They are intended to be used (when using the shell at all)
as the root account.
Our environment also (due to a government contract) requires a two-tier
access scheme. US citizens on the team may access any host as root.
Non-US citizens may access only a subset of the hosts. The techniques
described in this article may be extended for
N tiers without any real
trouble, but I describe the case N == 2 in this article.
The Scenario
I am going to assume you, the reader, know how to set up an SSH trust
relationship so that an account on one host can log in directly, with no
password prompting, to an account on another. (Basically, you simply
create a key pair and copy the public half to the remote host's
~/.ssh/authorized_keys file.) If you don't know how to do this, stop
reading now and go learn. A Web search for "ssh trust setup" will yield
thousands of links—or, if you're old-school, the AUTHENTICATION section
of the ssh(1) man page will do. Also see ssh-copy-id(1), which can greatly
simplify the distribution of key files.
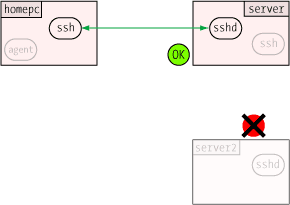
Steve Friedl's Web site has an excellent Tech Tip on these basics, plus some
material on SSH agent-forwarding, which is a neat trick to centralize SSH
authentication for an individual user. The Tech Tip is available at
http://www.unixwiz.net/techtips/ssh-agent-forwarding.html.
I describe key-caching below, as it is not very commonly used and is
the heart of the technique described herein.
For illustration, I'm assigning names to players (individuals assigned to
roles), the tiers of access and "dummy" accounts.
Hosts:
-
darter — the hostname of the central management host on which all the
end-user and utility accounts are active, all keys are stored and caching
takes place; also, the sudoers file controlling access to utility accounts
is here.
-
n1, n2, ... — hostnames of target hosts for which access is to be granted
for all team members ("n" for
"non-special").
-
s1, s2, ... — hostnames of target hosts for which access is to be granted
only to some team members ("s" for
"special").
Accounts (on darter only):
-
univ — the name of the utility account holding the SSH keys that all
target hosts (u1, u2, ...) will trust.
-
spec — the name of the utility account holding the SSH keys that only
special, restricted-access, hosts (s1, s2, ...) will trust.
-
joe — let's say the name of the guy administering the whole scheme
is "Joe" and his account is "joe". Joe is a
trusted admin with "the keys to
the kingdom"—he cannot be a restricted user.
-
andy, amy — these are users who are allowed to log in to all hosts.
-
alice
-
ned, nora — these are users who are allowed to log in
only to "n"
(non-special) hosts; they never should be allowed to log in to special
hosts s1, s2, ...
-
nancy
You will want to create shared, unprivileged utility accounts on darter for
use by unrestricted and restricted admins. These (per our convention) will
be called "univ" and "rstr", respectively. No one should actually directly
log in to univ and rstr, and in fact, these accounts should not have
passwords or trusted keys of their own. All logins to the shared utility
accounts should be performed with su(1) from an existing individual account
on darter.
The Setup
Joe's first act is to log in to darter and "become" the univ account:
$ sudo su - univ
Then, under that shared utility account, Joe creates a .ssh directory and
an SSH keypair. This key will be trusted by the root account on every
target host (because it's the "univ"-ersal key):
$ mkdir .ssh # if not already present
$ ssh-keygen -t rsa -b 2048 -C "universal access
↪key gen YYYYMMDD" -f
.ssh/univ_key
Enter passphrase (empty for no passphrase):
Very important: Joe assigns a strong passphrase to this key. The
passphrase to this key will not be generally shared.
(The field after
-C is merely a comment; this format reflects my personal
preference, but you are of course free to develop your own.)
This will generate two files in .ssh: univ_key (the private key file) and
univ_key.pub (the public key file). The private key file is encrypted,
protected by the very strong passphrase Joe assigned to it, above.
Joe logs out of the univ account and into rstr. He executes the same
steps, but creates a keypair named rstr_key instead of univ_key. He
assigns a strong passphrase to the private key file—it can be the same
passphrase as assigned to univ, and in fact, that is probably preferable
from the standpoint of simplicity.
Joe copies univ_key.pub and rstr_key.pub to a common location for
convenience.
For every host to which access is granted for everyone (n1, n2, ...), Joe
uses the target hosts' root credentials to copy
both univ_key.pub and
rstr_key.pub (on separate lines) to the file .ssh/authorized_keys under the
root account directory.
For every host to which access is granted for only a few (s1, s2, ...), Joe
uses the target hosts' root credentials to copy
only rstr_key.pub (on a
single line) to the file .ssh/authorized_keys under the root account
directory.
So to review, now, when a user uses
su to "become" the univ account, he or
she can log in to
any host, because univ_key.pub exists in the
authorized_keys file of n1, n2, ... and s1, s2, ....
However, when a user uses
su to "become" the rstr account, he or she can
log in
only to n1, n2, ..., because those hosts' authorized_keys files
contain rstr_key.pub, but
not univ_key.pub.
Of course, in order to unlock the access in both cases, the user will need
the strong passphrase with which Joe created the keys. That seems to
defeat the whole purpose of the scheme, but there's a trick to get around
it.
The Trick
First, let's talk about key-caching.
Any user who uses SSH keys whose key files are protected by a passphrase
may cache those keys using a program called ssh-agent. ssh-agent does not
take a key directly upon invocation. It is invoked as a standalone
program without any parameters (at least, none useful to us here).
The output of ssh-agent is a couple environment variable/value pairs,
plus an echo command, suitable for input to the shell. If you invoke it
"straight", these variables will not become part of the environment. For
this reason, ssh-agent always is invoked as a parameter of the shell
built-in
eval:
$ eval $(ssh-agent)
Agent pid 29013
(The output of
eval also includes an echo statement to show you the PID of
the agent instance you just created.)
Once you have an agent running, and your shell knows how to communicate
with it (thanks to the environment variables), you may cache keys with it
using the command
ssh-add. If you give
ssh-add a key file, it will prompt
you for the passphrase. Once you provide the correct passphrase, ssh-agent
will hold the unencrypted key in memory. Any invocation of SSH will check
with ssh-agent before attempting authentication. If the key in memory
matches the public key on the remote host, trust is established, and the
login simply happens with no entry of passwords or passphrases.
(As an aside: for those of you who use the Windows terminal program PuTTY,
that tool provides a key-caching program called Pageant, which performs
much the same function. PuTTY's equivalent to ssh-keygen is a utility
called PuTTYgen.)
All you need to do now is set it up so the univ and rstr accounts set
themselves up on every login to make use of persistent instances of
ssh-agent. Normally, a user manually invokes ssh-agent upon login, makes
use of it during that session, then kills it, with
eval
$(ssh-agent -k),
before exiting. Instead of manually managing it, let's write into each
utility account's .bash_profile some code that does the following:
-
First, check whether there is a current instance of ssh-agent for the
current account.
-
If not, invoke ssh-agent and capture the environment variables in a
special file in /tmp. (It should be in /tmp because the contents of /tmp
are cleared between system reboots, which is important for managing cached
keys.)
-
If so, find the file in /tmp that holds the environment variables
and source it into the shell's environment.
(Also, handle the error case where the agent is running and the /tmp file
is not found by killing ssh-agent and starting from scratch.)
All of the above assumes the key already has been unlocked and cached. (I
will come back to that.)
Here is what the code in .bash_profile looks like for the univ account:
/usr/bin/pgrep -u univ 'ssh-agent' >/dev/null
RESULT=$?
if [[ $RESULT -eq 0 ]] # ssh-agent is running
then
if [[ -f /tmp/.env_ssh.univ ]] # bring env in to session
then
source /tmp/.env_ssh.univ
else # error condition
echo 'WARNING: univ ssh agent running, no environment
↪file found'
echo ' ssh-agent being killed and restarted ... '
/usr/bin/pkill -u univ 'ssh-agent' >/dev/null
RESULT=1 # due to kill, execute startup code below
fi
if [[ $RESULT -ne 0 ]] # ssh-agent not running, start
↪it from scratch
then
echo "WARNING: ssh-agent being started now;
↪ask Joe to cache key"
/usr/bin/ssh-agent > /tmp/.env_ssh.univ
/bin/chmod 600 /tmp/.env_ssh.univ
source /tmp/.env_ssh.univ
fi
And of course, the code is identical for the rstr account, except
s/univ/rstr/ everywhere.
Joe will have to intervene
once whenever darter (the central management
host on which all the user accounts and the keys reside) is restarted. Joe
will have to log on and become univ and execute the command:
$ ssh-add ~/.ssh/univ_key
and then enter the passphrase. Joe then logs in to the rstr account and
executes the same command against ~/.ssh/rstr_key. The command
ssh-add
-l lists cached keys by their fingerprints and filenames, so if there is
doubt about whether a key is cached, that's how to find out. A single
agent can cache multiple keys, if you have a use for that, but it doesn't
come up much in my environment.
Once the keys are cached, they will stay cached. (
ssh-add -t
may be
used to specify a timeout of
N seconds, but you won't want to use that
option for this shared-access scheme.) The cache must be rebuilt for each
account whenever darter is rebooted, but since darter is a Linux host, that
will be a rare event. Between reboots, the single instance (one per
utility account) of ssh-agent simply runs and holds the key in memory.
The
last time I entered the passphrases of our utility account keys was more
than
500 days ago—and I may go several hundred more before having to do so
again.
The last step is setting up sudoers to manage access to the utility
accounts. You don't
really have to do this. If you like, you can set
(different) passwords for univ and rstr and simply let the users hold them.
Of course, shared passwords aren't a great idea to begin with. (That's one
of the major points of this whole scheme!) Every time one of the users of
the univ account leaves the team, you'll have to change that password and
distribute the new one (hopefully securely and out-of-band) to all the
remaining users.
No, managing access with sudoers is a better idea. This article isn't here
to teach you all of—or any of—the ins and outs of sudoers' Extremely
Bizarre Nonsensical Frustration (EBNF) syntax. I'll just give you the
cheat code.
Recall that Andy, Amy, Alice and so on were all allowed to access all hosts.
These users are permitted to use sudo to execute the
su -
univ command.
Ned, Nora, Nancy and so on are permitted to access only the restricted list of
hosts. They may log in only to the rstr account using the
su -
rstr
command. The sudoers entries for these might look like:
User_Alias UNIV_USERS=andy,amy,alice,arthur # trusted
User_Alias RSTR_USERS=ned,nora,nancy,nyarlathotep # not so much
# Note that there is no harm in putting andy, amy, etc. into
# RSTR_USERS as well. But it also accomplishes nothing.
Cmnd_Alias BECOME_UNIV = /bin/su - univ
Cmnd_Alias BECOME_RSTR = /bin/su - rstr
UNIV_USERS ALL= BECOME_UNIV
RSTR_USERS ALL= BECOME_RSTR
Let's recap. Every host n1, n2, n3 and so on has
both univ and rstr key files in
authorized_keys.
Every host s1, s2, s3 and so on has
only the univ key file in
authorized_keys.
When darter is rebooted, Joe logs in to both the univ and rstr accounts and
executes the ssh-add command with the private key file as a parameter. He
enters the passphrase for these keys when prompted.
Now Andy (for example) can log in to darter, execute:
$ sudo su - univ
and authenticate with his password. He now can log in as root to
any of
n1, n2, ..., s1, s2, ... without further authentication. If Andy needs to
check the functioning of ntp (for example) on each of 20 hosts, he can
execute a loop:
$ for H in n1 n2 n3 [...] n10 s1 s2 s3 [...] s10
> do
> ssh -q root@$H 'ntpdate -q timeserver.domain.tld'
> done
and it will run without further intervention.
Similarly, nancy can log in to darter, execute:
$ sudo su - rstr
and log in to any of n1, n2 and so on, execute similar loops, and so forth.
Benefits and Risks
Suppose Nora leaves the team. You simply would edit sudoers to delete her from
RSTR_USERS, then lock or delete her system account.
"But Nora was fired for misconduct! What if she kept a copy of the
keypair?"
The beauty of this scheme is that access to the two key files
does not matter. Having the public key file isn't
important—put the public
key file on the Internet if you want. It's public!
Having the encrypted copy of the private key file doesn't matter. Without
the passphrase (which only Joe knows), that file may as well be the output
of /dev/urandom. Nora never had access to the raw key file—only the
caching agent did.
Even if Nora kept a copy of the key files, she cannot use them for access.
Removing her access to darter removes her access to every target host.
And the same goes, of course, for the users in UNIV_USERS as well.
There are two caveats to this, and make sure you understand them well.
Caveat the first: it (almost) goes without saying that anyone with root
access to darter obviously can just become root, then
su -
univ at any
time. If you give someone root access to darter, you are giving that
person full access to all the target hosts as well. That, after all, is
the meaning of saying the target hosts "trust" darter. Furthermore, a user
with root access who does not know the passphrase to the keys still
can recover the raw keys from memory with a little moderately sophisticated
black magic. (Linux memory architecture and clever design of the agent
prevent non-privileged users from recovering their own agents' memory
contents in order to extract keys.)
Caveat the second: obviously, anyone holding the passphrase can make (and
keep) an unencrypted copy of the private keys. In our example, only Joe
had that passphrase, but in practice, you will want two or three trusted
admins to know the passphrase so they can intervene to re-cache the keys
after a reboot of darter.
If anyone with root access to your central management host (darter, in this
example)
or anyone holding private key passphrases should leave the team,
you will have to generate new keypairs and replace the contents of
authorized_keys on every target host in your enterprise. (Fortunately, if
you are careful, you can use the old trust relationship to create the new
one.)
For that reason, you will want to entrust the passphrase only to
individuals whose positions on your team are at least reasonably stable.
The techniques described in this article are probably not suitable for a
high-turnover environment with no stable "core" admins.
One more thing about this:
you don't need to be managing tiered or any kind of shared access for this
basic trick to be useful. As I noted above, the usual way of using
an SSH
key-caching agent is by invoking it at session start, caching your key,
then killing it before ending your session. However, by including the code
above in your own .bash_profile, you can create your own file in /tmp,
check for it, load it if present and so on. That way, the host always has just
one instance of ssh-agent running, and your key is cached in it permanently
(or until the next reboot, anyway).
Even if you don't want to cache your key
that persistently, you still
can make use of a single ssh-agent and cache your key with the timeout (-t)
option mentioned earlier; you still will be saving yourself a step.
Note that if you do this, however, anyone with root on that host will have
access to any account of yours that trusts your account on that
machine— so
caveat actor. (I use this trick only on personal boxes that only I
administer.)
The trick for personal use is becoming obsolete, as Mac OS X (via SSHKeyChain)
and newer versions of GNOME (via Keyring) automatically
know the first
time you SSH to a host with which you have a key-based authentication set
up, then ask you your passphrase and cache the key for the rest of your GUI
login session. Given the lack of default timeouts and warnings about root
users' access to unlocked keys, I am not sure this is an unmixed
technological advance. (It is possible to configure timeouts in both
utilities, but it requires that users find out about the option, and take
the effort to configure it.)
Acknowledgements
I gratefully acknowledge the technical review and helpful suggestions of
David Scheidt and James Richmond in the preparation of this article.















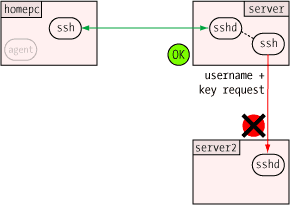
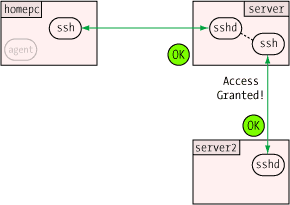
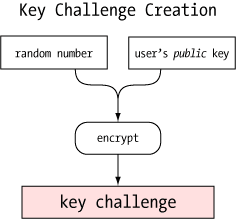 One of the more clever aspects of the agent is how it can verify
a user's identity (or more precisely, possession of a private key) without
revealing that private key to anybody. This, like so many other
things in modern secure communications, uses public key encryption.
One of the more clever aspects of the agent is how it can verify
a user's identity (or more precisely, possession of a private key) without
revealing that private key to anybody. This, like so many other
things in modern secure communications, uses public key encryption.
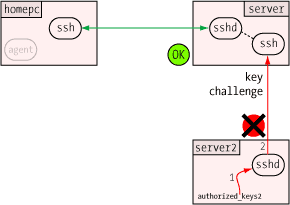
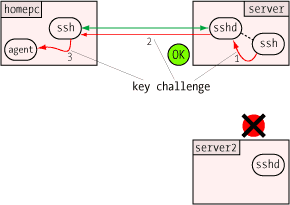
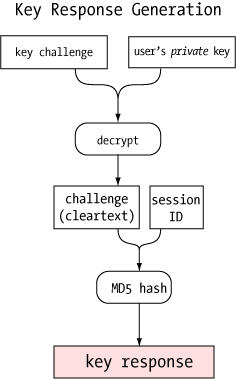 When the agent receives the challenge, it decrypts it with the private
key. If this key is the "other half" of the public key on the server,
the decryption will be successful, revealing the original random number
generated by the server. Only the holder of the private key could ever
extract this random number, so this constitutes proof that the user is
the holder of the private key.
When the agent receives the challenge, it decrypts it with the private
key. If this key is the "other half" of the public key on the server,
the decryption will be successful, revealing the original random number
generated by the server. Only the holder of the private key could ever
extract this random number, so this constitutes proof that the user is
the holder of the private key.
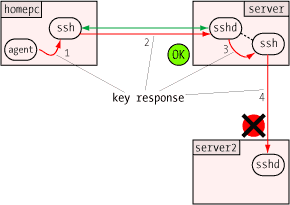
 One of the security benefits of agent forwarding is that the user's
private key never appears on remote systems or on the wire, even in
encrypted form. But the same agent protocol which shields the private
key may nevertheless expose a different vulnerability: agent hijacking.
One of the security benefits of agent forwarding is that the user's
private key never appears on remote systems or on the wire, even in
encrypted form. But the same agent protocol which shields the private
key may nevertheless expose a different vulnerability: agent hijacking.
 The Secure Shell: The Definitive Guide
The Secure Shell: The Definitive Guide