http://ask.xmodulo.com/check-cpu-info-linux.html
By inspecting this file, you can identify the number of physical processors, the number of cores per CPU, available CPU flags, and a number of other things.



Question: I would like to know detailed
information about the CPU processor of my computer. What are the
available methods to check CPU information on Linux?
Depending on your need, there are various pieces of information you
may need to know about the CPU processor(s) of your computer, such as
CPU vendor name, model name, clock speed, number of sockets/cores,
L1/L2/L3 cache configuration, available processor capabilities (e.g.,
hardware virtualization, AES, MMX, SSE), and so on. In Linux, there are
many command line or GUI-based tools that are used to show detailed
information about your CPU hardware.1. /proc/cpuinfo
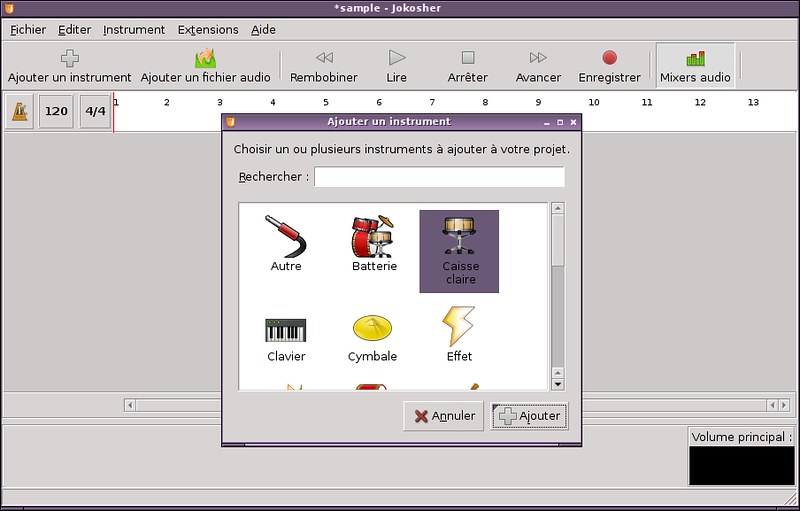
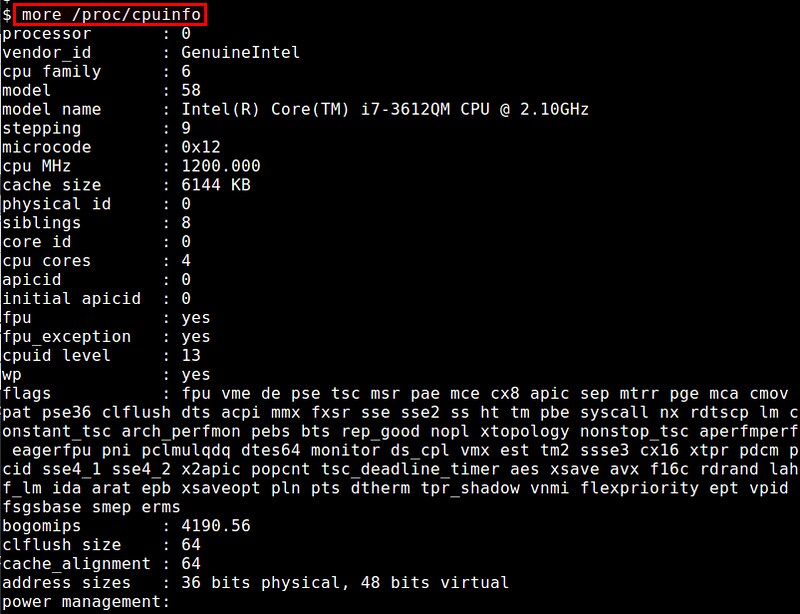
The simpliest method is to check /proc/cpuinfo. This virtual file shows the configuration of available CPU hardware.
$ more /proc/cpuinfo
By inspecting this file, you can identify the number of physical processors, the number of cores per CPU, available CPU flags, and a number of other things.
2. cpufreq-info
The cpufreq-info command (which is part of cpufrequtils package) collects and reports CPU frequency information from the kernel/hardware. The command shows the hardware frequency that the CPU currently runs at, as well as the minimum/maximum CPU frequency allowed, CPUfreq policy/statistics, and so on. To check up on CPU #0:
$ cpufreq-info -c 0
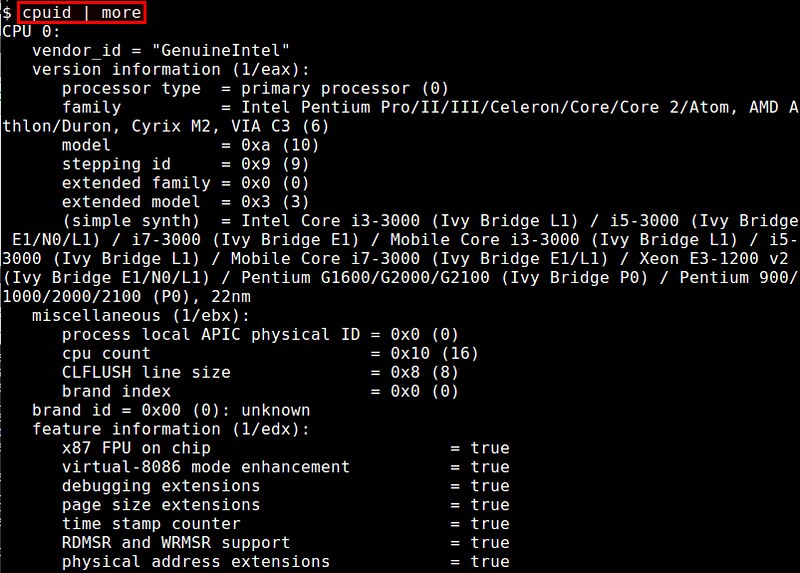
3. cpuid
The cpuid command-line utility is a dedicated CPU information tool that displays verbose information about CPU hardware by using CPUID functions. Reported information includes processor type/family, CPU extensions, cache/TLB configuration, power management features, etc.
$ cpuid
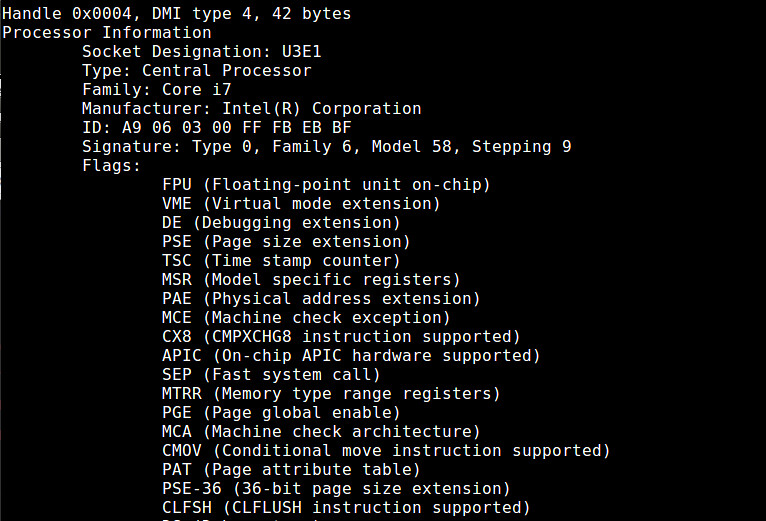
4. dmidecode
The dmidecode command collects detailed information about system hardware directly from DMI data of the BIOS. Reported CPU information includes CPU vendor, version, CPU flags, maximum/current clock speed, (enabled) core count, L1/L2/L3 cache configuration, and so on.
$ sudo dmidecode
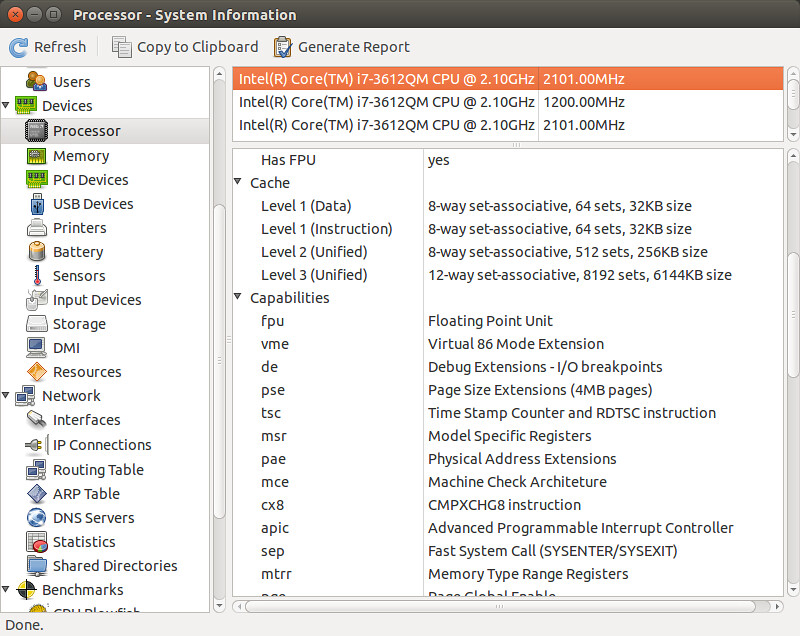
5. hardinfo
The hardinfo is a GUI-based system information tool which can give you an easy-to-understand summary of your CPU hardware, as well as other hardware components of your system.
$ hardinfo
6. inxi
inxi is a bash script written to gather system information in a human-friendly format. It shows a quick summary of CPU information including CPU model, cache size, clock speed, and supported CPU capabilities.
$ inxi -C
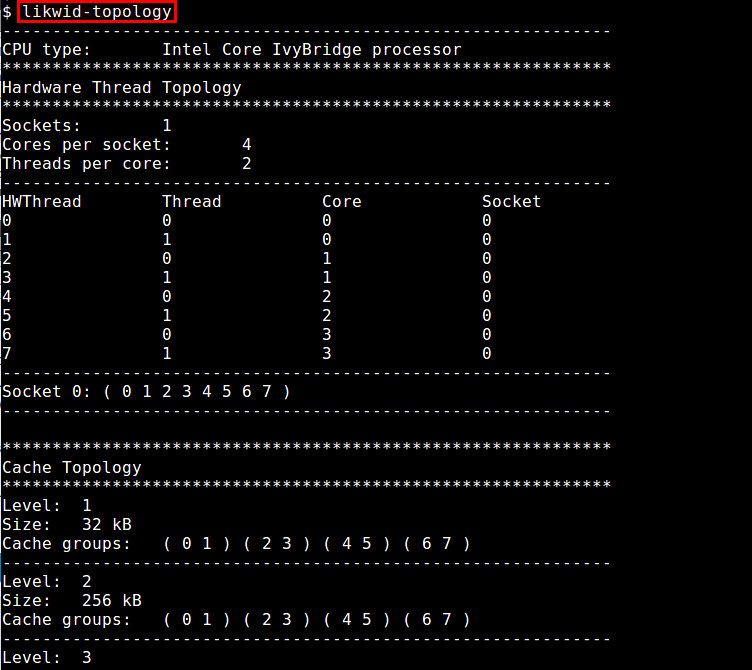
7. likwid-topology
likwid (Like I Knew What I'm Doing) is a collection of command-line tools to measure, configure and display hardware related properties. Among them is likwid-topology which shows CPU hardware (thread/cache/NUMA) topology information. It can also identify processor families (e.g., Intel Core 2, AMD Shanghai).8. lscpu
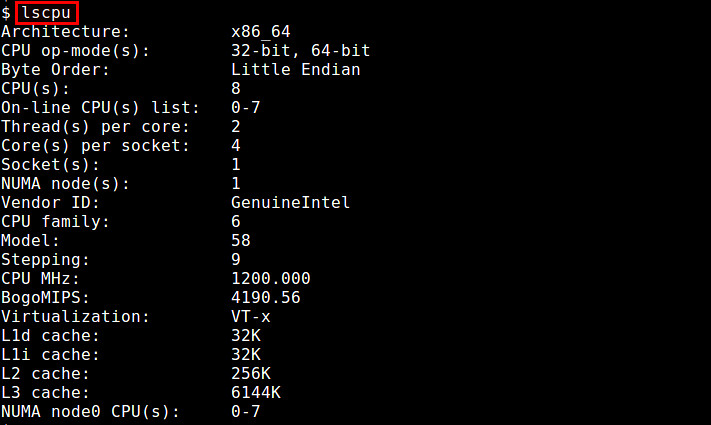
The lscpu command summarizes /etc/cpuinfo content in a more user-friendly format, e.g., the number of (online/offline) CPUs, cores, sockets, NUMA nodes.
$ lscpu
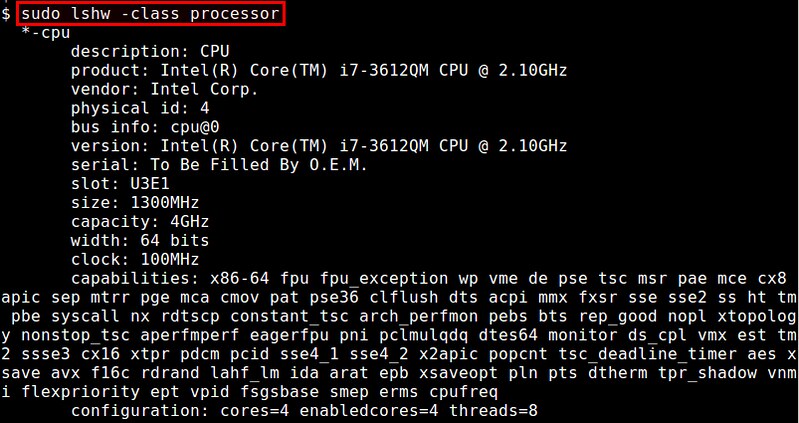
9. lshw
The lshw command is a comprehensive hardware query tool. Unlike other tools, lshw requires root privilege because it query DMI information in system BIOS. It can report the total number of cores and enabled cores, but miss out on information such as L1/L2/L3 cache configuration. The GTK version lshw-gtk is also available.
$ sudo lshw -class processor
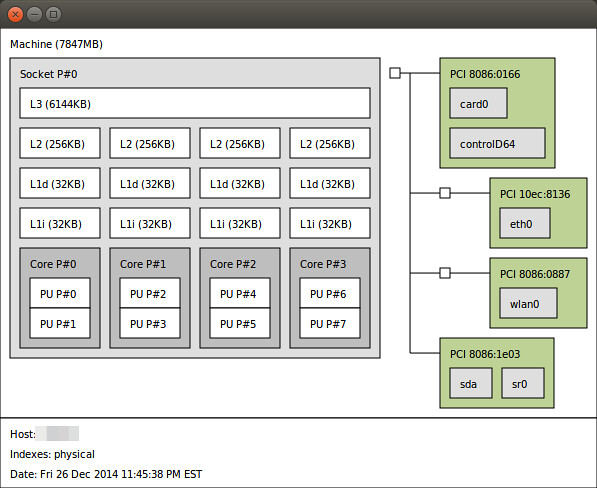
10. lstopo
The lstopo command (contained in hwloc package) visualizes the topology of the system which is composed of CPUs, cache, memory and I/O devices. This command is useful to identify the processor architecture and NUMA topology of the system.
$ lstopo
11. numactl
Originally developed to set the NUMA scheduling and memeory placement policy of Linux processes, the numactl command can also show information about NUMA topology of the CPU hardware from the command line.
$ numactl --hardware