http://www.openlogic.com/wazi/bid/351296/an-introduction-to-systemd-for-centos-7
With Red Hat Enterprise Linux 7 released and CentOS version 7 newly unveiled, now is a good time to cover systemd, the replacement for legacy System V (SysV) startup scripts and runlevels. Red Hat-based distributions are migrating to systemd because it provides more efficient ways of managing services and quicker startup times. With systemd there are fewer files to edit, and all the services are compartmentalized and stand separate from each other. This means that should you screw up one config file, it won't automatically take out other services.
Systemd has been the default system and services manager in Red Hat Fedora since the release of Fedora 15, so it is extensively field-tested. It provides more consistency and troubleshooting ability than SysV – for instance, it will report if a service has failed, is suspended, or is in error. Perhaps the biggest reason for the move to systemd is that it allows multiple services to start up at the same time, in parallel, making machine boot times quicker than they would be with legacy runlevels.
Under systemd, services are now defined in what are termed unit files, which are text files that contain all the configuration information a service needs to start, including its dependencies. Service files are located in /usr/lib/systemd/system/. Many but not all files in that directory will end in .service; systemd also manages sockets and devices.
No longer do you directly modify scripts to configure runlevels. Within systemd, runlevels have been replaced by the concept of states. States can be described as "best efforts" to get a host into a desired configuration, whether it be single-user mode, networking non-graphical mode, or something else. Systemd has some predefined states created to coincide with legacy runlevels. They are essentially aliases, designed to mimic runlevels by using systemd.
States require additional components above and beyond services. Therefore, systemd uses unit files not only to configure services, but also mounts, sockets, and devices. These units' names end in .sockets, .devices, and so on.
Targets, meanwhile, are logical groups of units that provide a set of services. Think of a target as a wrapper in which you can place multiple units, making a tidy bundle to work with.
Unit files are built from several configurable sections, including unit descriptions and dependencies. Systemd also allows administrators to explicitly define a service's dependencies and load them before the given service starts by editing the unit files. Each unit file has a line that starts
Targets have more meaningful names than those used in SysV-based systems. A name like graphical.target gives admins an idea of what a file will provide! To see the current target at which the system is residing, use the command
Another important feature systemd implements is cgroups, short for control groups, which provide security and manageability for the resources a system can use and control. With cgroups, services that use the same range of underlying operating system calls are grouped together. These control groups then manage the resources they control. This grouping performs two functions: it allows administrators to manage the amount of resources a group of services gets, and it provides additional security in that a service in a certain cgroup can't jump outside of cgroups control, preventing it for example from getting access to other resources controlled by other cgroups.
Cgroups existed in the old SysV model, but were not really implemented well. systemd attempts to fix this issue.
How can you start managing systemd services? Now that Centos 7 is out
of the starting gate we can start to experiment with systemd and
understand its operation. To begin, as the root user in a terminal, type
Red Hat-based OSes no longer use the old /etc/initab file, but instead use a system.default configuration file. You can symlink a desired target to the system.default in order to have that target start up when the system boots. To configure the target to start a typical multi-user system, for example, run the command below:

In the same vein, use
To see all the services you can start using systemctl and their statuses, use the command

While you can no longer enable a runlevel for a service using
With Red Hat Enterprise Linux 7 released and CentOS version 7 newly unveiled, now is a good time to cover systemd, the replacement for legacy System V (SysV) startup scripts and runlevels. Red Hat-based distributions are migrating to systemd because it provides more efficient ways of managing services and quicker startup times. With systemd there are fewer files to edit, and all the services are compartmentalized and stand separate from each other. This means that should you screw up one config file, it won't automatically take out other services.
Systemd has been the default system and services manager in Red Hat Fedora since the release of Fedora 15, so it is extensively field-tested. It provides more consistency and troubleshooting ability than SysV – for instance, it will report if a service has failed, is suspended, or is in error. Perhaps the biggest reason for the move to systemd is that it allows multiple services to start up at the same time, in parallel, making machine boot times quicker than they would be with legacy runlevels.
Under systemd, services are now defined in what are termed unit files, which are text files that contain all the configuration information a service needs to start, including its dependencies. Service files are located in /usr/lib/systemd/system/. Many but not all files in that directory will end in .service; systemd also manages sockets and devices.
No longer do you directly modify scripts to configure runlevels. Within systemd, runlevels have been replaced by the concept of states. States can be described as "best efforts" to get a host into a desired configuration, whether it be single-user mode, networking non-graphical mode, or something else. Systemd has some predefined states created to coincide with legacy runlevels. They are essentially aliases, designed to mimic runlevels by using systemd.
States require additional components above and beyond services. Therefore, systemd uses unit files not only to configure services, but also mounts, sockets, and devices. These units' names end in .sockets, .devices, and so on.
Targets, meanwhile, are logical groups of units that provide a set of services. Think of a target as a wrapper in which you can place multiple units, making a tidy bundle to work with.
Unit files are built from several configurable sections, including unit descriptions and dependencies. Systemd also allows administrators to explicitly define a service's dependencies and load them before the given service starts by editing the unit files. Each unit file has a line that starts
After= that can be used to define what service is required before the current service can start. WantedBy=lines specify that a target requires a given unit.Targets have more meaningful names than those used in SysV-based systems. A name like graphical.target gives admins an idea of what a file will provide! To see the current target at which the system is residing, use the command
systemctl get-default. To set the default target, use the command systemctl set-default targetname.target. targetname can be, among others:- rescue.target
- multi-user.target
- graphical.target
- reboot.target
Another important feature systemd implements is cgroups, short for control groups, which provide security and manageability for the resources a system can use and control. With cgroups, services that use the same range of underlying operating system calls are grouped together. These control groups then manage the resources they control. This grouping performs two functions: it allows administrators to manage the amount of resources a group of services gets, and it provides additional security in that a service in a certain cgroup can't jump outside of cgroups control, preventing it for example from getting access to other resources controlled by other cgroups.
Cgroups existed in the old SysV model, but were not really implemented well. systemd attempts to fix this issue.
First steps in systemd
Under systemd you can still use the service and chkconfig commands to manage those additional legacy services, such as Apache, that have not yet been moved over to systemd management. You can also use service command to manage systemd-enabled services. However, several monitoring and logging services, including cron and syslog, have been rewritten to use the functionality that is available in systemd, in part because scheduling and some of the cron functionality is now provided by systemd.
You can also manage systemd with a GUI management tool called systemd
System Manger, though it is not usually installed by default. To
install it, as root, run yum -y install systemd-ui. |
chkconfig. The output shows all the legacy services
running. As you can see by the big disclaimer, most of the other
services that one would expect to be present are absent, because they
have been migrated to systemd management.Red Hat-based OSes no longer use the old /etc/initab file, but instead use a system.default configuration file. You can symlink a desired target to the system.default in order to have that target start up when the system boots. To configure the target to start a typical multi-user system, for example, run the command below:
ln -sf /lib/systemd/system/multi-user.target /etc/systemd/system/default.targetAfter you make the symlink, run
systemctl, the replacement for chkconfig. Several pages of output display, listing all the services available:
- Unit – the service name
- Load – gives status of the service (such as Loaded, Failed, etc.)
- Active – indicates whether the status of the service is Active
- Description – textual description of the unit
systemctl start postfix.service.In the same vein, use
systemctl stop and systemctl status to stop services or view information. This syntax similarity to chkconfig arguments is by design, to make the transition to systemd as smooth as possible.To see all the services you can start using systemctl and their statuses, use the command
systemctl list-unit-files --type=service
While you can no longer enable a runlevel for a service using
chkconfig --level, under systemd you can enable or disable a service when it boots. Use systemctl enable service to enable a service, and systemctl disable service to keep it from starting at boot. Get a service's current status (enabled or disabled) with the command systemctl is-enabled service.

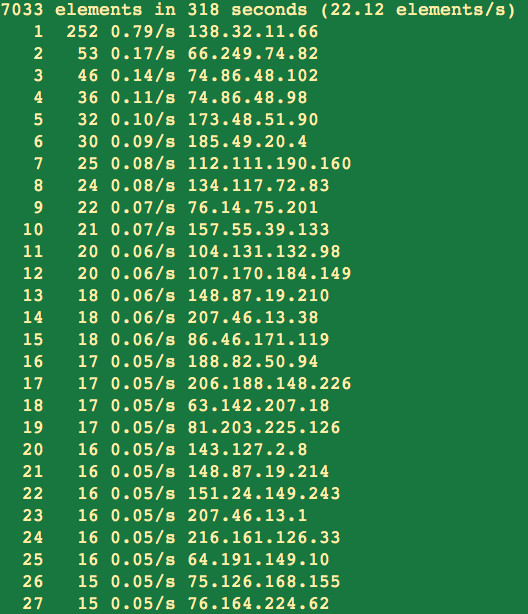
 The IP address against which the services are mapped needs to be
reachable at all time. Normally Heartbeat would assign the designated IP
address to a virtual network interface card (NIC) on the primary server
for you. If the primary server goes down, the cluster will
automatically shift the IP address to a virtual NIC on another of its
available servers. When the primary server comes back online, it shifts
the IP address back to the primary server again. This IP address is
called "floating" because of its migratory properties.
The IP address against which the services are mapped needs to be
reachable at all time. Normally Heartbeat would assign the designated IP
address to a virtual network interface card (NIC) on the primary server
for you. If the primary server goes down, the cluster will
automatically shift the IP address to a virtual NIC on another of its
available servers. When the primary server comes back online, it shifts
the IP address back to the primary server again. This IP address is
called "floating" because of its migratory properties.


 Georgia Tech
Georgia Tech



